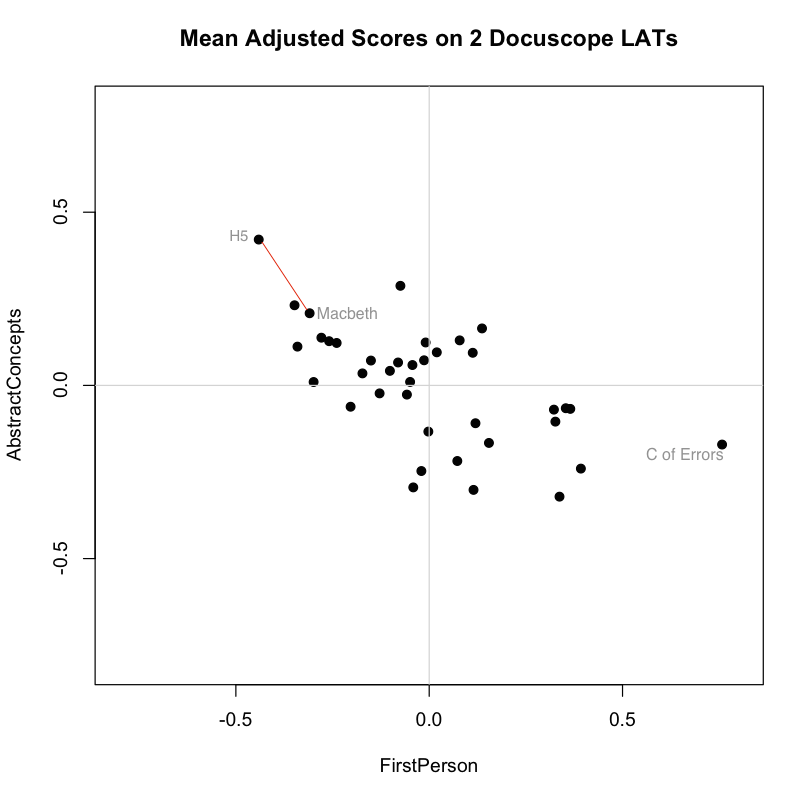
It’s hard to conceive of distance measured in anything other than a straight line. The biplot below, for example, shows the scores of Shakespeare’s plays on the two Docuscope LATs discussed in the previous post, FirstPerson and AbstractConcepts:
 Plotting the items in two dimensions gives the viewer some general sense of the shape of the data. “There are more items here, less there.” But when it comes to thinking about distances between texts, we often measure straight across, favoring either a simple line linking two items or a line that links the perceived centers of groups.
Plotting the items in two dimensions gives the viewer some general sense of the shape of the data. “There are more items here, less there.” But when it comes to thinking about distances between texts, we often measure straight across, favoring either a simple line linking two items or a line that links the perceived centers of groups.
The appeal of the line is strong, perhaps because it is one dimensional. And brutally so. We favor the simple line because want to see less, not more. Even if we are looking at a biplot, we can narrow distances to one dimension by drawing athwart the axes. The red lines linking points above — each the diagonal of a right triangle whose sides are parallel to our axes — will be straight and relatively easy to find. The line is simple, but its meaning is somewhat abstract because it spans two distinct kinds of distance at once.
Distances between items become slightly less abstract when things are represented in an ordered list. Scanning down the “text_name” column below, we know that items further down have less of the measured feature that those further up. There is a sequence here and, so, an order of sorts:
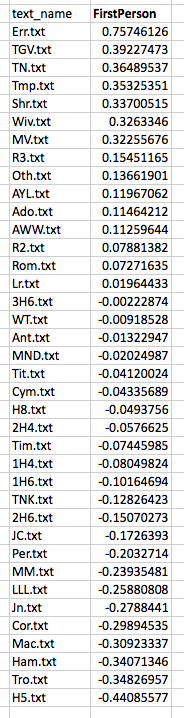
If we understand what is being measured, an ordered list can be quite suggestive. This one, for example, tells me that The Comedy of Errors has more FirstPerson tokens than The Tempest. But it also tells me, by virtue of the way it arranges the plays along a single axis, that the more FirstPerson Shakespeare uses in a play, the more likely it is that this play is a comedy. There are statistically precise ways of saying what “more” and “likely” mean in the previous sentence, but you don’t need those measures to appreciate the pattern.
What if I prefer the simplicity of an ordered list, but want nevertheless to work with distances measured in more than one dimension? To get what I want, I will have to find some meaningful way of associating the measurements on these two dimensions and, by virtue of that association, reducing them to a single measurement on a new (invented) variable. I want distances on a line, but I want to derive those distances from more than one type of measurement.
My next task, then, will be to quantify the joint participation of these two variables in patterns found across the corpus. Instead of looking at both of the received measurements (scores on FirstPerson and AbstractConcepts), I want to “project” the information from these two axes onto a new, single axis, extracting relevant information from both. This projection would be a reorientation of the data on a single new axis, a change accomplished by Principal Components Analysis or PCA.
To understand better how PCA works, let’s continue working with the two LATs plotted above. Recall from the previous post that these are the Docuscope scores we obtained from Ubiqu+ity and put into mean deviation form. A .csv file containing those scores can be found here. In what follows, we will be feeding those scores into an Excel spreadsheet and into the open source statistics package “R” using code repurposed from a post on PCA at Cross Validated by Antoni Parellada.
A Humanist Learns PCA: The How and Why
As Hope and I made greater use of unsupervised techniques such as PCA, I wanted a more concrete sense of how it worked. But to arrive at that sense, I had to learn things for which I had no visual intuition. Because I lack formal training in mathematics or statistics, I spent about two years (in all that spare time) learning the ins and outs of linear algebra, as well as some techniques from unsupervised learning. I did this with the help of a good textbook and a course on linear algebra at Kahn Academy.
Having learned to do PCA “by hand,” I have decided here to document that process for others wanting to try it for themselves. Over the course of this work, I came to a more intuitive understanding of the key move in PCA, which involves a change of basis via orthogonal projection of the data onto a new axis. I spent many months trying to understood what this means, and am now ready to try to explain or illustrate it to others.
My starting point was an excellent tutorial on PCA by Jonathon Shlens. Schlens shows why PCA is a good answer to a good question. If I believe that my measurements only incompletely capture the underlying dynamics in my corpus, I should be asking what new orthonormal bases I can find to maximize the variance across those initial measurements and, so, provide better grounds for interpretation. If this post is successful, you will finish it knowing (a) why this type of variance-maximizing basis is a useful thing to look for and (b) what this very useful thing looks like.
On the matrix algebra side, PCA can be understood as the projection of the original data onto a new set of orthogonal axes or bases. As documented in the Excel spreadsheet and the tutorial, the procedure is performed on our data matrix, X, where entries are in mean deviation form (spreadsheet item 1). Our task is then to create a 2×2 a covariance matrix S for this original 38×2 matrix X (item 2); find the eigenvalues and eigenvectors for this covariance matrix X (item 3); then use this new matrix of orthonormal eigenvectors, P, to accomplish the rotation of X (item 4). This rotation of X gives us our new matrix Y (item 5), which is the linear transformation of X according to the new orthonormal bases contained in P. The individual steps are described in Shlens and reproduced on this spreadsheet in terms that I hope summarize his exposition. (I stand ready to make corrections.)
The Spring Analogy
In addition to exploring the assumptions and procedures involved in PCA, Shlens offers a suggestive concrete frame or “toy example” for thinking about it. PCA can be helpful if you want to identify underlying dynamics that have been both captured and obscured by initial measurements of a system. He stages a physical analogy, proposing the made-up situation in which the true axis of movement of a spring must be inferred from haphazardly positioned cameras A, B and C. (That movement is along the X axis.)
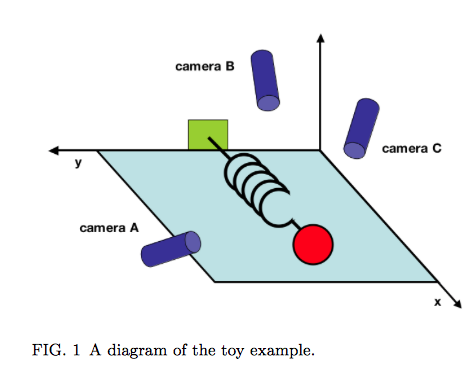
Shlens notes that “we often do not know which measurements best reflect the dynamics of our system in question. Furthermore, we sometimes record more dimensions than we actually need!” The idea that the axis of greatest variance is also the axis that captures the “underlying dynamics” of the system is an important one, particularly in a situation where measurements are correlated. This condition is called multicollinearity. We encounter it in text analysis all the time.
If one is willing to entertain the thought that (a) language behaves like a spring across a series of documents and (b) that LATs are like cameras that only imperfectly capture those underlying linguistic “movements,” then PCA makes sense as a tool for dimension reduction. Shlens makes this point very clearly on page 7, where he notes that PCA works where it works because “large variances have important dynamics.” We need to spend more time thinking about what this linkage of variances and dynamics means when we’re talking about features of texts. We also need to think more about what it means to treat individual documents as observations within a larger system whose dynamics they are assumed to express.
Getting to the Projections
How might we go about picturing this mathematical process of orthogonal projection? Shlens’s tutorial focuses on matrix manipulation, which means that it does not help us visualize how the transformation matrix P assists in the projection of the original matrix onto the new bases. But we want to arrive at a more geometrically explicit, and so perhaps intuitive, way of understanding the procedure. So let’s use the code I’ve provided for this post to look at the same data we started with. These are the mean-subtracted values of the Docuscope LATs AbstractConcepts and FirstPerson in the Folger Editions of Shakespare’s plays. 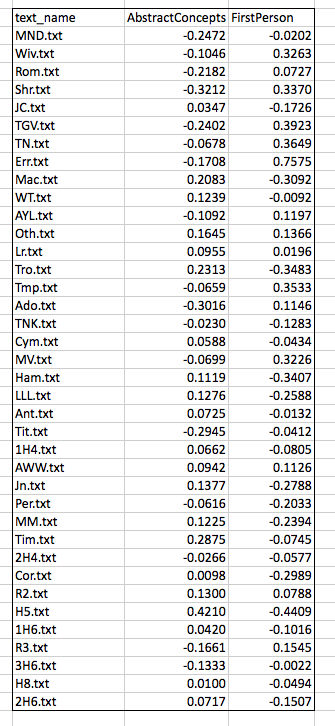 To get started, you must place the .csv file containing the data above into your R working directory, a directory you can change using the the Misc. tab. Paste the entire text of the code in the R prompt window and press enter. Within that window, you will now see several means of calculating the covariance matrix (S) from the initial matrix (X) and then deriving eigenvectors (P) and final scores (Y) using both the automated R functions and “longhand” matrix multiplication. If you’re checking, the results here match those derived from the manual operations documented the Excel spreadsheet, albeit with an occasional sign change in P. In the Quartz graphic device (a separate window), we will find five different images corresponding to five different views of this data. You can step through these images by keying control-arrow at the same time.
To get started, you must place the .csv file containing the data above into your R working directory, a directory you can change using the the Misc. tab. Paste the entire text of the code in the R prompt window and press enter. Within that window, you will now see several means of calculating the covariance matrix (S) from the initial matrix (X) and then deriving eigenvectors (P) and final scores (Y) using both the automated R functions and “longhand” matrix multiplication. If you’re checking, the results here match those derived from the manual operations documented the Excel spreadsheet, albeit with an occasional sign change in P. In the Quartz graphic device (a separate window), we will find five different images corresponding to five different views of this data. You can step through these images by keying control-arrow at the same time.
The first view is a centered scatterplot of the measurements above on our received or “naive bases,” which are our two docuscope LATs. These initial axes already give us important information about distances between texts. I repeat the biplot from the top of the post, which shows that according to these bases, Macbeth is the second “closest” play to Henry V (sitting down and to the right of Troilus and Cressida, which is first):
Now we look at the second image, which adds to the plot above a line that is the eigenvector corresponding to the highest eigenvalue for the covariance matrix S. This is the line that, by definition, maximizes the variance in our two dimensional data: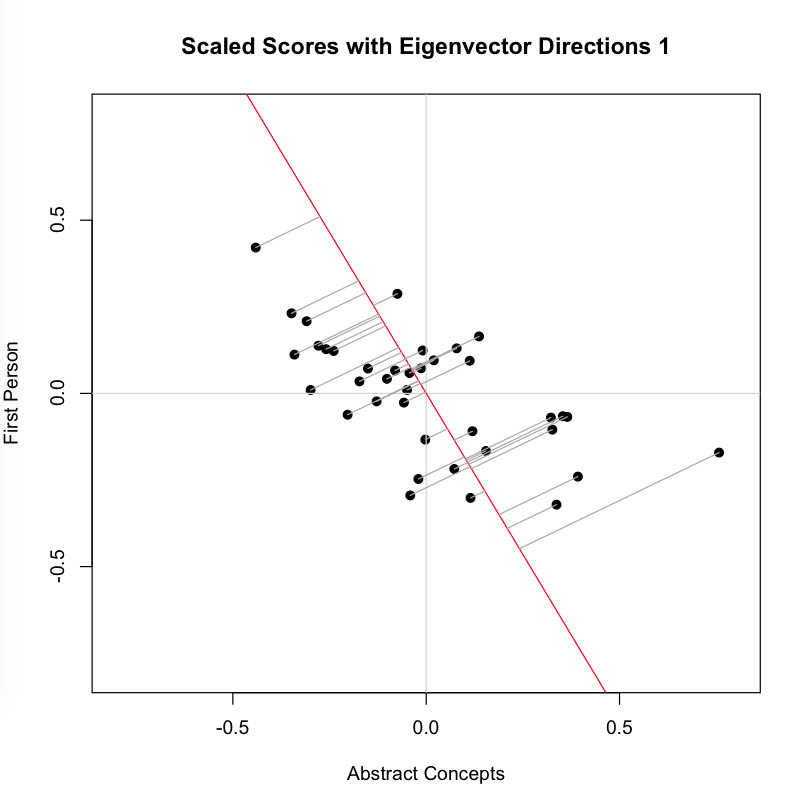 You can see that each point is projected orthogonally on to this new line, which will become the new basis or first principal component once the rotation has occurred. This maximum is calculated by summing the squared distances of each the perpendicular intersection point (where gray meets red) from the mean value at the center of the graph. This red line is like the single camera that would “replace,” as it were, the haphazardly placed cameras in Shlens’s toy example. If we agree with the assumptions made by PCA, we infer that this axis represents the main dynamic in the system, a key “angle” from which we can view that dynamic at work.
You can see that each point is projected orthogonally on to this new line, which will become the new basis or first principal component once the rotation has occurred. This maximum is calculated by summing the squared distances of each the perpendicular intersection point (where gray meets red) from the mean value at the center of the graph. This red line is like the single camera that would “replace,” as it were, the haphazardly placed cameras in Shlens’s toy example. If we agree with the assumptions made by PCA, we infer that this axis represents the main dynamic in the system, a key “angle” from which we can view that dynamic at work.
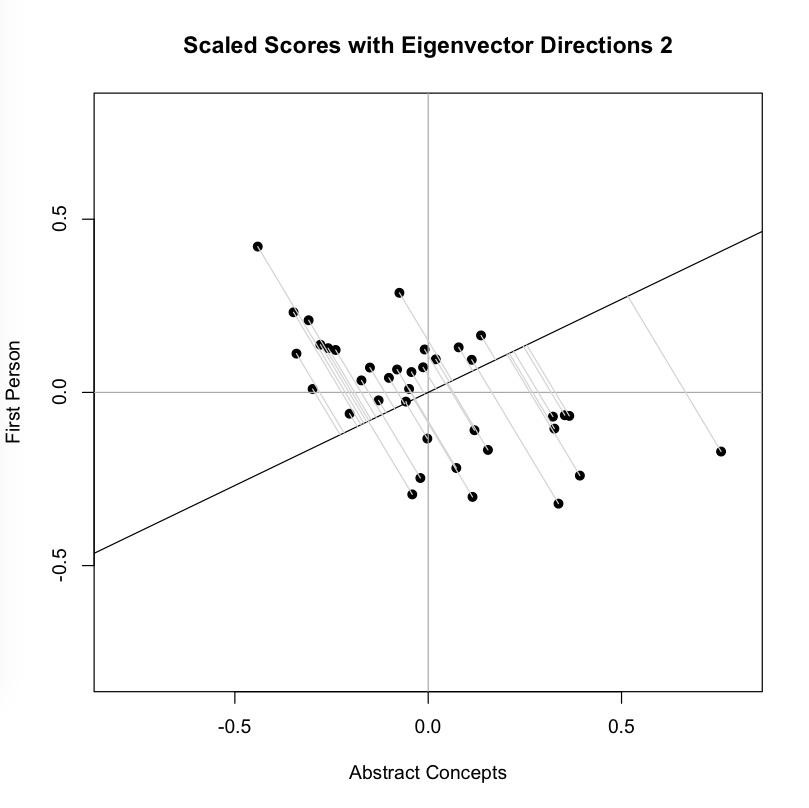
The orthonormal assumption makes it easy to plot the next line (black), which is the eigenvector corresponding to our second, lesser eigenvalue. The measured distances along this axis (where gray meets black) represents scores on the second basis or principal component, which by design eliminates correlation with the first. You might think of the variance along this line is the uncorrelated “leftover” from the that which was captured along the first new axis. As you can see, intersection points cluster more closely around the mean point in the center of this line than they did around the first:
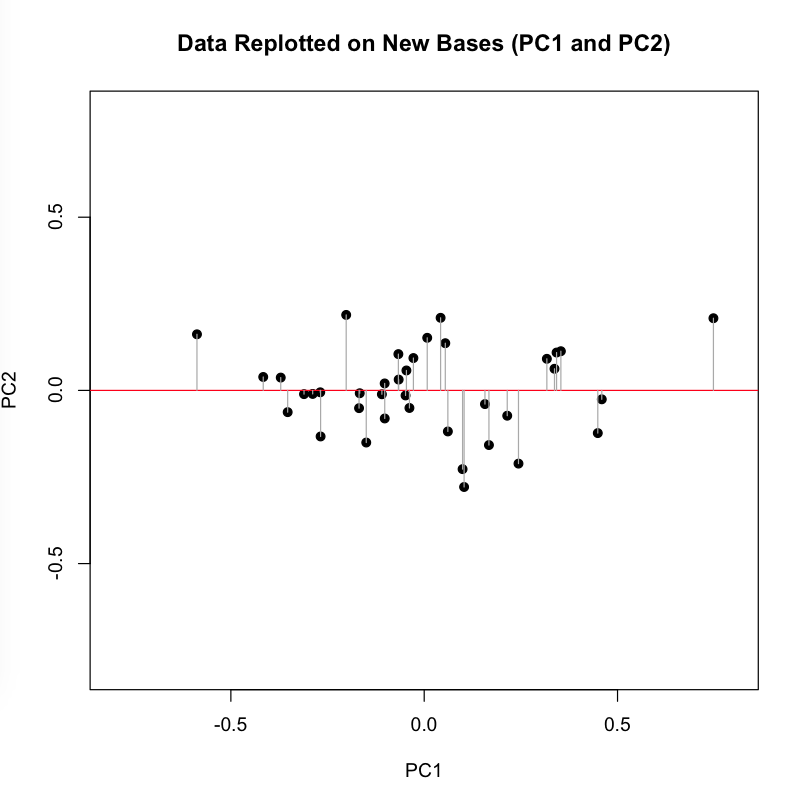
 Now we perform the change of basis, multiplying the initial matrix X by the transformation matrix P. This projection (using the gray guide lines above) onto the new axis is a rotation of the original data around the origin. For the sake of explication, I highlight the resulting projection along the first component in red, the axis that (as we remember) accounts for the largest amount of variance:
Now we perform the change of basis, multiplying the initial matrix X by the transformation matrix P. This projection (using the gray guide lines above) onto the new axis is a rotation of the original data around the origin. For the sake of explication, I highlight the resulting projection along the first component in red, the axis that (as we remember) accounts for the largest amount of variance:
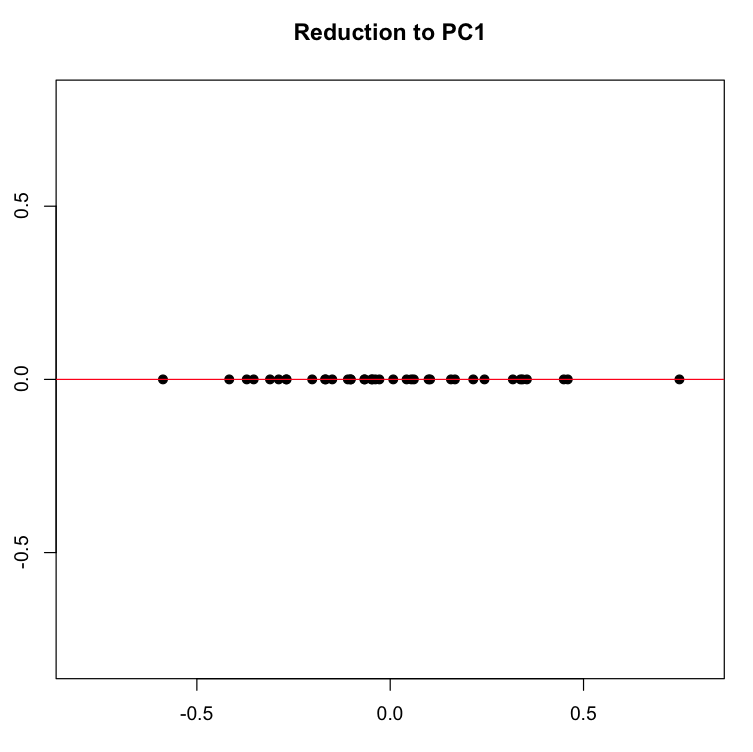
 If we now force all of our dots onto the red line along their perpendicular gray pathways, we eliminate the second dimension (Y axis, or PC2), projecting the data onto a single line, which is the new basis represented by the first principal component.
If we now force all of our dots onto the red line along their perpendicular gray pathways, we eliminate the second dimension (Y axis, or PC2), projecting the data onto a single line, which is the new basis represented by the first principal component.
We can now create a list of the plays ranked, in descending order, on this first and most principal component. This list of distances represents the reduction of the two initial dimensions to a single one, a reduction motivated by our desire to capture the most variance in a single direction.
How does this projection change the distances among our items? The comparison below shows the measurements, in rank order, of the far ends of our initial two variables (AbstractConcepts and FirstPerson) and of our new variable (PC1). You can see that the plays have been re-ordered and the distances between them changed:
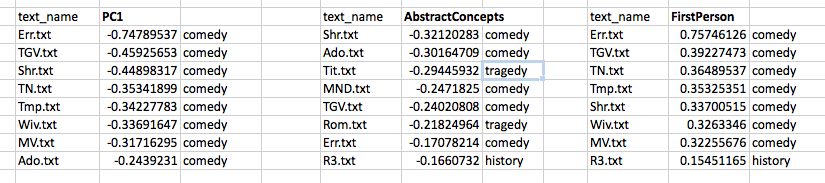
Our new basis, PC1, looks like it is capturing some dynamic that we might connect to the what the creators of the First Folio (1623) labeled as “comedy.” When we look at similar ranked lists for our initial two variables, we see that individually they too seemed to be connected with “comedy,” in the sense that a relative lack of one (AbstractConcepts) and an abundance of the other (FirstPerson) both seem to contribute to a play’s being labelled a comedy. Recall that these two variables showed a negative covariance in the initial analysis, so this finding is unsurprising.
But what PCA has done is combined these two variables into a new one, which is a linear combination of the scores according to weighted coefficients (found in the first eigenvector). If you are low on this new variable, you are likely to be a comedy. We might want to come up with a name for PC1, which represents the combined, re-weighted power of the first two variables. If we call it the “anti-comedy” axis — you can’t be comic if you have a lot of it! — then we’d be aligning the sorting power of this new projection with what literary critics and theorists call “genre.” Remember that by aligning these two things is not the same as saying one is the cause of the other.
With a sufficient sample size, this procedure for reducing dimensions could be performed on a dozen measurements or variables, transforming that naive set of bases into principal components that (a) maximize the variance in the data and, one hopes, (b) call attention to the dynamics expressed in texts conceived as “system.” If you see PCA performed on three variables rather than two, you should imagine the variance-maximizing-projection above repeated with a plane in the three dimensional space:
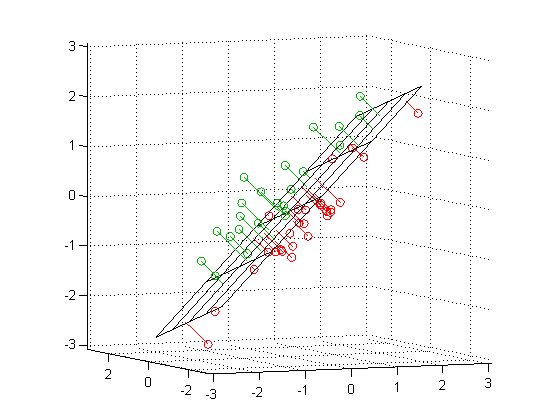
Add yet another dimension, and you can still find the “hyperplane” which will maximize the variance along a new basis in that multidimensional space. But you will not be able to imagine it.
Because principal components are mathematical artifacts — no one begins by measuring an imaginary combination of variables — they must be interpreted. In this admittedly contrived example from Shakespeare, the imaginary projection of our existing data onto the first principal component, PC1, happens to connect meaningfully with one of the sources of variation we already look for in cultural systems: genre. A corpus of many more plays, covering a longer period of time and more authors, could become the basis for still more projections that would call attention to other dynamics we want to study, for example, authorship, period style, social coterie or inter-company theatrical rivalry.
I end by emphasizing the interpretability of principal components because we humanists may be tempted to see them as something other than mathematical artifacts, which is to say, something other than principled creations of the imagination. Given the data and the goal of maximizing variance through projection, many people could come up with the same results that I have produced here. But there will always be a question about what to call the “underlying dynamic” a given principal component is supposed to capture, or even about whether a component corresponds to something meaningful in the data. The ongoing work of interpretation, beginning with the task of naming what a principal component is capturing, is not going to disappear just because we have learned to work with mathematical — as opposed to literary critical — tools and terms.
Axes, Critical Terms, and Motivated Fictions
Let us return to the idea that a mathematical change of basis might call our attention to an underlying dynamic in a “system” of texts. If, per Shlens’s analogy, PCA works by finding the ideal angle from which to view the oscillations of the spring, it does so by finding a better proxy for the underlying phenomenon. PCA doesn’t give you the spring, it gives you a better angle from which to view the spring. There is nothing about the spring analogy or about PCA that contradicts the possibility that the system being analyzed could be much more complicated — could contain many more dynamics. Indeed, there nothing to stop a dimension reduction technique like PCA from finding dynamics that we will never be able to observe or name.
Part of what the humanities do is cultivate empathy and a lively situational imagination, encouraging us to ask, “What would it be like to be this kind of person in this kind of situation?” That’s often how we find our way into plays, how we discover “where the system’s energy is.” But the humanities is also a field of inquiry. The enterprise advances every time someone refines one of our explanatory concepts and critical terms, terms such as “genre,” “period,” “style,” “reception,” or “mode of production.”
We might think of these critical terms as the humanities equivalent of a mathematical basis on which multidimensional data are projected. Saying that Shakespeare wrote “tragedies” reorients the data and projects a host of small observations on a new “axis,” as it were, an axis that somehow summarizes and so clarifies a much more complex set of comparisons and variances than we could ever state economically. Like geometric axes, critical terms such as “tragedy” bind observations and offer new ways of assessing similarity and difference. They also force us to leave things behind.
The analogy between a mathematical change of basis and the application of critical terms might even help explain what we do to our colleagues in the natural and data sciences. Like someone using a transformation matrix to re-project data, the humanist introduces powerful critical terms in order to shift observation, drawing some of the things we study closer together while pushing others further apart. Such a transformation or change of basis can be accomplished in natural language with the aid of field-structuring analogies or critical examples. Think of the perspective opened up by Clifford Geertz’s notion of “deep play,” or his example of the Balinese cock fight, for example. We are also adept at making comparisons that turn examples into the bases of new critical taxonomies. Consider how the following sentence reorients a humanist problem space: “Hamlet refines certain tragic elements in The Spanish Tragedy and thus becomes a representative example of the genre.”
For centuries, humanists have done these things without the aid of linear algebra, even if matrix multiplication and orthogonal projection now produce parallel results. In each case, the researcher seeks to replace what Shlens calls a “naive basis” with a motivated one, a projection that maps distances in a new and powerful way.
Consider, as a final case study in projection, the famous speech of Shakespeare’s Jacques, who begins his Seven Ages of Man speech with the following orienting move: “All the world’s a stage, / And all the men and women merely players.” With this analogy, Jacques calls attention to a key dynamic of the social system that makes Shakespeare’s profession possible — the fact of pervasive play. Once he has provided that frame, the ordered list of life roles falls neatly into place.
This ability to frame an analogy or find an orienting concept —the world is a stage, comedy is a pastoral retreat, tragedy is a fall from a great height, nature is a book — is something fundamental to humanities thinking, yet it is necessary for all kinds of inquiry. Improvising on a theme from Giambattista Vico, the intellectual historian Hans Blumenberg made this point in his work on foundational analogies that inspire conceptual systems, for example the Stoic theater of the universe or the serene Lucretian spectator looking out on a disaster at sea. In a number of powerful studies — Shipwreck with Spectator, Paradigms for a Metaphorology, Care Crosses the River — Blumenberg shows how analogies such as these come to define entire intellectual systems; they even open those systems to sudden reorientation.
We certainly need to think more about why mathematics might allow us to appreciate unseen dynamics in social systems, and how critical terms in the humanities allow us to communicate more deliberately about our experiences. How startling that two very different kinds of fiction — a formal conceit of calculation and the enabling, partial slant of analogy — help us find our way among the things we study. Perhaps this should not be surprising. As artifacts, texts and other cultural forms are staggeringly complex.
I am confident that humanists will continue to seek alternative views on the complexity of what we study. I am equally confident that our encounters with that complexity will remain partial. By nature, analogies and computational artifacts obscure some things in order to reveal other things: the motivation of each is expressed in such tradeoffs. And if there is no unmotivated view on the data, the true dynamics of the cultural systems we study will always withdraw, somewhat, from the lamplight of our descriptive fictions.