Michael Witmore & Jonathan Hope
Over 61,000 texts were transcribed by the TCP project, everything from hunting manuals to weapon inventories to lyric poems and plays. Important work is being done on this corpus, and it is clear that we are nowhere near exhausting the possible analyses that can be conducted on a dataset of this size (well over 1Bn words). One of the greatest challenges to working with the corpus is that the metadata for its contents — information about the texts that have been transcribed — is inconsistent or absent. If we want to characterize types of writing with the help of statistics, we must first label the items to be compared. To distinguish scientific writing from what was written for the stage, say, we must first ask someone to apply these labels to the relevant items. And labeling involves interpretation. A major challenge we face as researchers peering into this collection, then, is that of identifying what is being compared in the absence of human curated groups.
There is another way into the problem, which is so focus solely on the correlations or dependencies among variables — the fact that certain measured features track with and away from one another. We can do this in an unsupervised way, without reference to any human generated metadata. Here we find techniques such as principal component analysis (PCA), which we have used in our own studies. Other unsupervised techniques that do not rely on human generated ground truths would be word embeddings (Word2Vec, Glove) and cluster analysis (K-means, etc). In our past work with Shakespeare, we used unsupervised techniques to see whether this “hands off” exploration of patterns in the data lined up with groupings that humans have already made. We conducted that research on dozens of items rather than a corpus of tens of thousands. That research suggested to us that dependencies among text features track reasonably well with the domain judgments of literary experts. We have always wanted do this type of analysis on a larger scale, but have to this point been stymied by lack of human created metadata for genre.
One solution to this lack of metadata would be to take a smaller sample of labeled data grouped by genre, date, or some other criterion, and train an algorithm to identify other, unlabeled members of the group. This technique, called semi-supervised machine learning, leverages human judgment and speeds search in spaces where full metadata is unavailable. Most people take advantage of this partial leveraging of human insights when they search the internet. This method is not appealing to us, however, because it introduces a circularity in the work. Yes, it would be useful to train a classifier that finds poetry in a corpus where no one thought to look. But our goal is not to improve search. Rather, we want to understand, quantitatively and rhetorically, what it is at the level of textual features that would lead a human being to apply a label, as literary critics inevitably do. It’s the behavior that is interesting.
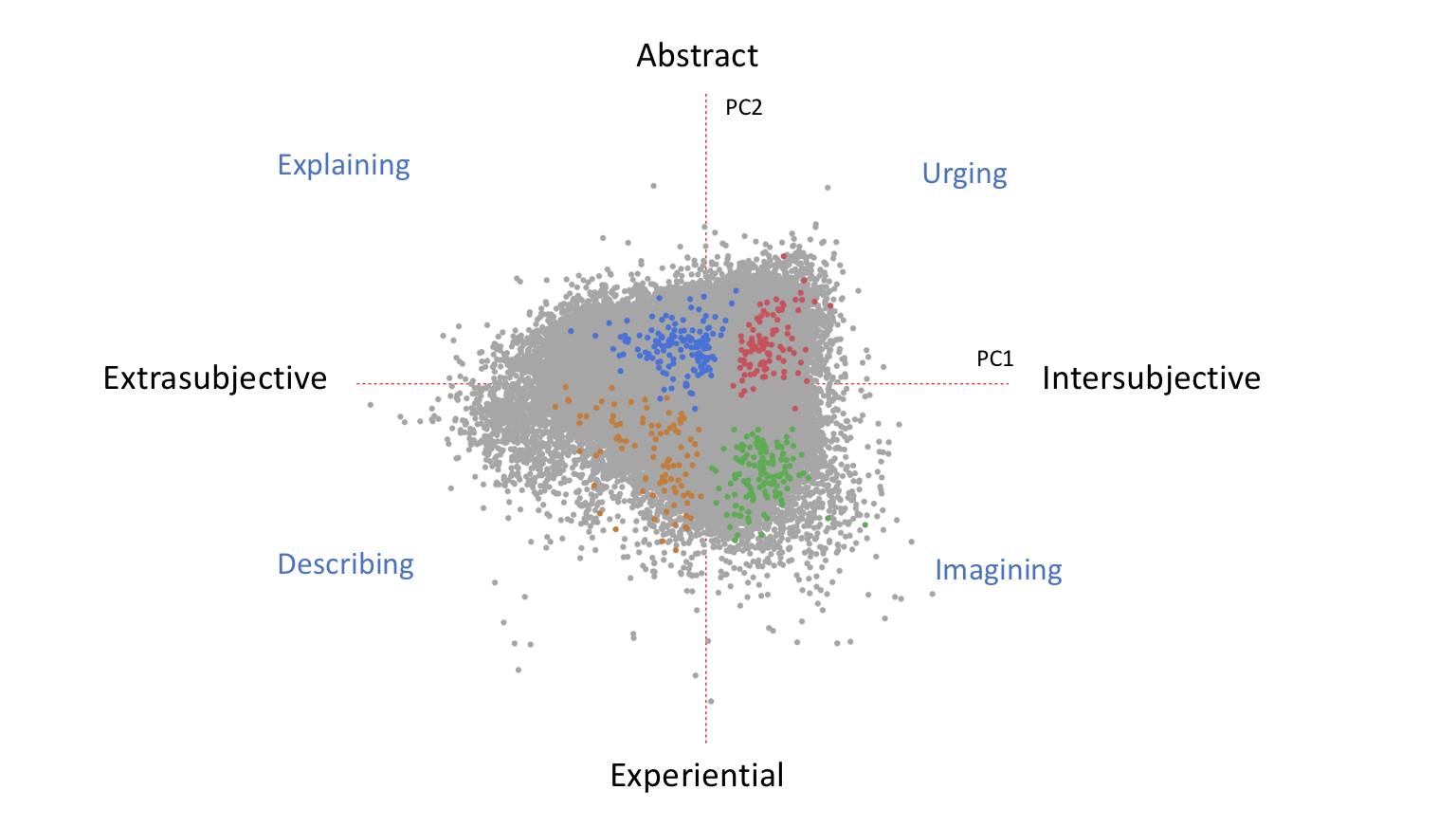
This extended blog post asks how our initial approach of comparing unsupervised analysis with independent human judgements would play out if we were to make such comparisons on a larger scale. Such comparisons present a challenge when every item in the TCP corpus has not yet been assigned genre labels by a human whose judgment we trust. A way forward presented itself, however, when the Mellon “Visualizing English Print” project at the University of Wisconsin funded the curation of a sub-corpus of 1080 texts, each of which was assigned a genre label by a team with domain expertise. These texts were drawn randomly from both the EEBO-TCP and ECCO-TCP, 40 per decade, beginning in 1530 and ending in 1799. Taking these 1080 texts as our starting point, we conducted an unsupervised analysis of the the subcorpus using PCA on a group of pre-selected features we had used before — Docuscope’s Language Action Types (LATs).[1] Those principal components were highly interpretable, leading us to propose two statistically-derived, feature-based oppositions that characterize the entire subcorpus. Each principal component expresses the tendency for texts have some features while lacking others. A map of these tendencies appears at the top of this post. What follows in the next section is an analysis that supports the interpretation of this first, map-like diagram.
Since these oppositions or axes are mathematically orthogonal, we take advantage of the further opportunity to explore a “four corner” distribution of text types across the two initial rhetorical oppositions. Here too we find that the corner combinations of paired traits (two from each axis) are also interpretable. In confirming those intuitions, we want to suggest again that — on a larger scale than before — unsupervised analysis of defined textual features aligns well with human judgments that never focused on those features. The fact that two independent ways of grouping texts converge is interesting in and of itself, and offers new opportunities to think about generic variation in early modern print texts.
But we make a second finding that is more interesting. The patterns arrived at through an unsupervised analysis of 1080 texts are just as discernible, just as dominant, in the full corpus of 61,000 texts. The original four-corner distribution of the labelled 1080 texts is preserved when PCA is performed on the full corpus. This continuity suggests that the map we created of the smaller group — one that shows four basic types of writing distributed around two basic oppositions — can be used to characterize the rhetorical dynamics present in the full TCP.
Each of these aspects of the exploration are taken up below in sections treating (1) unsupervised PCA of a subcorpus and our characterization of the PCs using examples; (2) the superimposition of labeled genres onto these derived components; (3) a study of combinations of the PCs that can be used to create a four quadrant rhetorical map of the corpus; and (4) an application of this map to the full TCP. Our goal in publishing the blog post is to demonstrate how one might use unsupervised techniques to redescribe dynamics in a corpus that lacks full metadata, and to do so “from the bottom up,” using examples. The resulting document is long, but we feel it captures every link in the chain of reasoning, including the examples that came to inform our interpretive choices.
Principal Components 1 and 2: Abstract/Experiential, Intersubjective/Extrasubjective
Principal component analysis or PCA is a well understood statistical technique for describing the dominant directions of variance in a dataset. The technique is often viewed as rudimentary in comparison to other techniques of dimension reduction. This is because PCA assumes linear relationships among the features counted in texts: it draws straight lines in a dataspace, whereas more custom “classifiers” can curve around exceptions. But PCA’s requirement that components be independent (mathematically orthogonal) means we can understand the relationships among components in a way that is geometrically intuitive. In this section we try to understand the components derived from the 1080 corpus and then map them onto a space that we can interpret.
PCA works by drawing a new axis or basis in a space containing as many dimensions as there are features counted. If we are measuring 115 different features, each of which is a Docuscope’s LAT, the new axis (PC1) is drawn in a 115 dimensional space, oriented in such a way as to maximize the “spread” of items across the component. A principal component, then, is a mathematical artifact that functions as a kind of binary recipe. It says, “Here are certain features that texts have in abundance (in order of prevalence) while simultaneously lacking others (in order of relative absence), described in purely mathematical terms.”
The first principal component (PC1) produced in the analysis describes a pattern that we call Abstract/Experiential. Texts scoring high on PC1 tend to relate matters according to the necessity of argument, logical entailment, or moral obligation. We call texts scoring high on PC1 Abstract, and those that score low Experiential. PC1 represents the difference between what is and what must be; it covers what gets related via the mediation of concepts and arguments (Abstract) versus a world of sensory experience (Experiential). Abstract texts work to guide readers through relationships of logical entailment or social obligation with some argumentative apparatus. Experiential texts, on the other hand, tend to relate person-to-object or person-to-event relationships in the first person, but not person-to-person relationships.
The second principal component (PC2) spans a continuum we are calling Intersubjective/Extrasubjective. Dynamics along this span are uncorrelated with the action we see on the first (described by PC1). Intersubjective texts depict the inner lives of people who are coming into contact with one another, whereas Extrasubjective texts convey impersonal relationships among abstractions and/or physical objects — relationships that are not disclosed via the inner life of a specific person. Intersubjective texts tell us why people are doing what they are doing, and disclose information as it relates to evolving intentions and circumstances. Extrasubjective texts, by contrast, present a world whose existence sits at arm’s length from the inner life of any particular onlooker or speaker. Extrasubjective texts assume the givenness of concepts/objects that are then placed in some kind of logical/spatial relationship with one another.
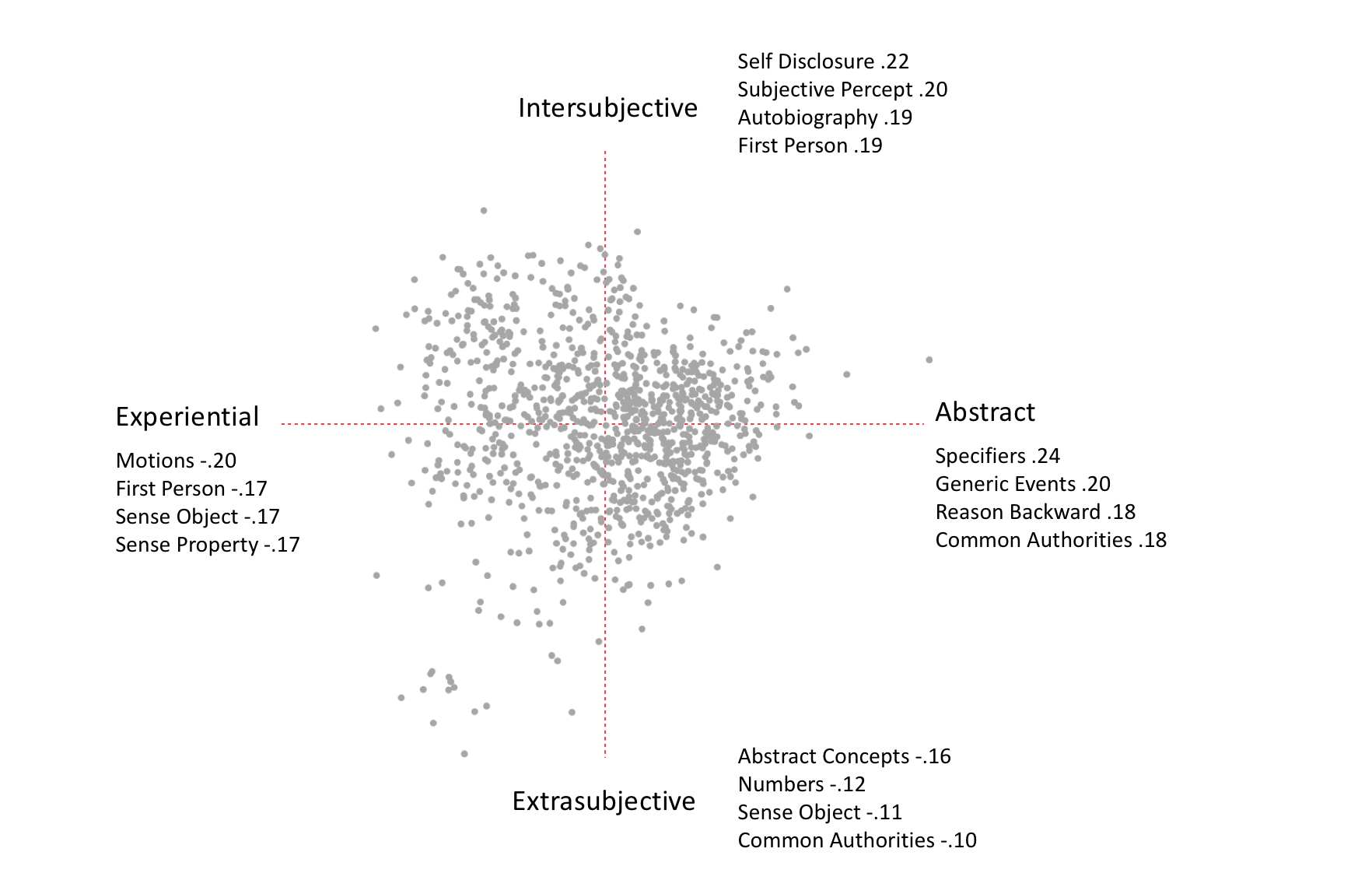
Both components are represented in the biplot below, which spreads items out according to their scores on each. So that readers can have a sense of the the placement of the examples we are about to discuss, we highlight the position of the example texts discussed below in this section:

Readers will notice a series of names under each of the directions in the biplot (“Self Disclosure .22” under the Intersubjective pole of PC2, for example). These names identify LATs that contribute positively or negatively to an item’s score on a component. Position on the x-axis, for example, is a function of an item’s having and/or lacking the LATs listed at either end of the axis. The LATs contributing to a text’s high score on the Abstract pole of PC1 — the LATs that move it to the right of the plot — are Specifiers, GenericEvents, ReasonBackward, and CommonAuthorities. Conversely, LATs lowering a text’s score on PC1, moving it to the Experiential pole at left, are Motions, FirstPerson, SenseObject, and SenseProperty. So too, Intersubjective texts at the top of the plot are characterized by high scores on SelfDisclosure, SubjectivePercept, Autobiography, and FirstPerson, whereas Extrasubjective texts have high scores on AbstractConcepts, Numbers, SenseObjects, and CommonAuthorities.
The names we have given to the component axes here are interpretive. We arrived at these interpretations by using a tool created by the VEP project — the SlimTV viewer — which offers color coded versions of the texts that correspond to the different features counted in the analysis. That tool allowed us to inspect the relevant (strongly loaded) LATs in context using example texts at the far ends of both axes. We move now to explore twelve of those examples. The views we present use color coding to call out the LATs (words and sequences of words) that are pushing items to the far end of the axes, making them good examples. The SlimTV viewer allows interactions through a browser, so readers can independently consult full, LAT-highlighted HTML versions of the twelve examples discussed below by following the links. We present an abundance of examples (and links to full tagged text) so that readers can understand how we arrived at these distinctions — Abstract/Experiential, Intersubjective/Extrasubjective. Readers are invited to skip ahead or explore further as necessary.
Abstract example 1: George Berkeley, Passive Obedience (1712), tagged text, plain text.

Berkeley’s treatise on the rational grounds for submitting to civil power guides its reader through a series of intellectual possibilities, using abstract nouns to shorthand the particular political situations (“cases,” “Occasions”) that he wants to subsume under general headings. This is the flow of logical argumentation, where the process of reasoning itself is managed through the use of (blue) Specifiers that show where the narrator is in the argument (“concerning a”, “in which every”, “concerning a”). Red GenericEvents words detach a moral or political action from any specific actor (“to be” done, “Actions”) so that it can be related to broader obligations (“Doctrine,” “necessity, “the Common Weal”), which Docuscope tags as (purple) CommonAuthority. A verb, “premised,” tagged as (green) ReasonBackward, connects a prior argument to a more recent one. An exemplary Abstract text, Berkeley’s treatise uses these characteristic words and phrases to coordinate a flow of ideas within and for a well-ordered mind.
Abstract example 2: William Prynne [attributed], The Long Parliament twice defunct (1660), tagged text, plain text.
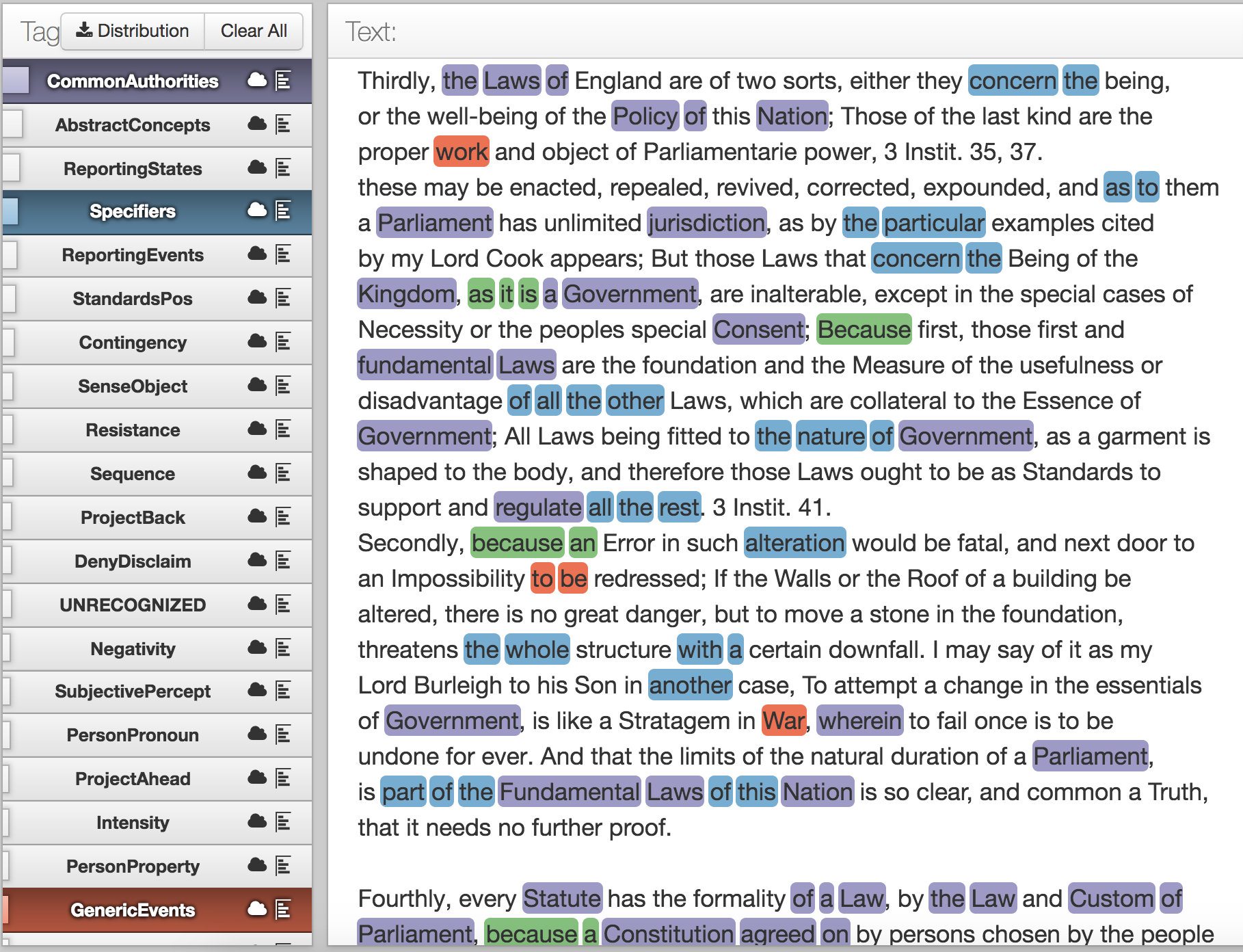
In Prynne’s treatise on the dissolution of the Long Parliament, we see the author placing a set of (purple) CommonAuthority nouns — “Government,” “Fundamental laws” — in logical relation to one another via the (green) ReasonBackward words (“because”, “as it is”). Prynne provides a window onto the process of ideas unfolding in a well-regulated mind, where the flow is motivated by relations of logical entailment rather than a contingent sequence of historical events. The scope of reference is restricted or directed with specifiers (“the whole”, “all the rest”, “part of the”), words that are necessary here because all reasons do not apply to all things. The language in this passage works to keep concepts from descending into particulars. That general elevation is accomplished through the use of (purple) CommonAuthority nouns on the one hand and — on the other — analogies that refer to no specific historical situation. He refers to housebuilding in general, for example, not the construction of a specific gatehouse in Blackfriars. Prynne’s text manages the attention of the reader by making sure particulars of any one person’s experience do not come to qualify his abstract claims.
Abstract example 3: Edward Fowler, Certain Propositions, By which the Doctrine of the H[oly] Trinity Is So Explained (1694), tagged text, plain text.
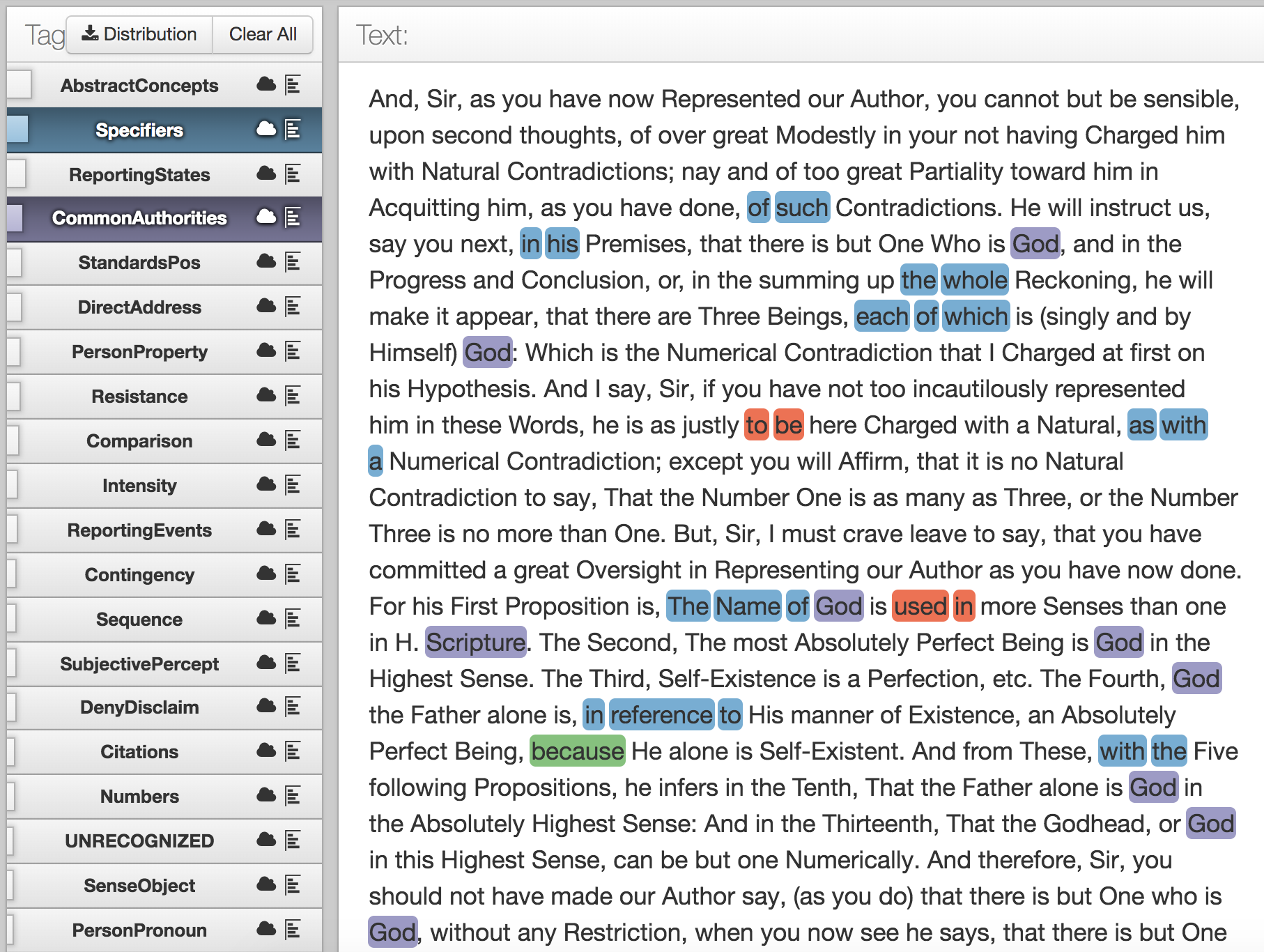
Edward Fowler is a Gloucestershire Bishop who, in Certain Propositions, sets out to defend claims about the Trinity from criticism. In doing so, he coordinates the objections of his opponent with his own refutations, adducing distinctions from another text to warrant his response. Not surprisingly given the context, (purple) CommonAuthority words — “God” and “Scripture” — are prominent, as are (blue) Specifiers that identify precisely which parts of an earlier argument he is addressing (“in reference to,” “with the,” “each of which”, “the whole”). The most frequently tagged phrase under (red) GenericEvents is “to be,” a passive construction that allows the writer to introduce a judgment (“justly to be here Charged”) without himself taking ownership of that judgment.
Experiential example 1: Jerningham, Yarico to Inkle (1766), tagged text, plain text.

Yarico to Inkle is a “heroic epistle” by a late 18th century English nobleman; it is delivered in the voice of Yarico, a female African slave who rescues a European mariner, only to have him turn on her and sell her (and their child) into slavery. This first textual example of the Experiential pole lacks the logical connectives and abstraction of its opposites above; what holds together the flow of items as expressed in the text is a consciousness that characterizes entities based on sensory properties. At one moment, we are focused on the ear and what it hears — “accents”, “waves”, the “limpid Stream.” These words co-occur with (blue) Motion words that generate the sensory layer being reported. Here is the stream that “glides”, the sail that flies, the “tempest-beaten” side, the “flow” of language from lips. The verbs highlighted in the example indicate a change in state of a physical thing, often a body, as opposed to some more generic reference to an event (as we saw in the examples on the other end of PC1). It should be no surprise that the (blue) motion verbs accompany other items tagged as (green) SenseObjects — “stream”, “bower”, “sea”, “lips”. Finally, the (red) FirstPerson tokens anchor this flow of sensation to the narrator who is the collecting center of that sensory experience.
Experiential example 2: Kane O’Hara, The Golden Pippin (1773), tagged text, plain text.

The Golden Pippin is an eighteenth century burletta written by the Irish composer Kane O’Hara. In Pippin, characters express outsized feelings about events in the narrative through individual arias, all reliant on the use of (red) FirstPerson LATs (here, “I” and “my”). As one might expect in a story about an apple (“pippin”), there are plenty of opportunities to name (green) SenseObjects and their (purple) SenseProperties in vivid language (“windows,” “wifes,” “puppets,” “Sky,” “Sultanas,” “Pippin,” “dripping,” “running,” “tripping” tagged with SenseProperty and SenseObject). But the language also conjures things and actions that are not being enacted onstage. The singer here, a fantastical character named Momus, describes how he will torment others — “On wires I dance ‘em all.” A text in which actions (past, imaginary, or future) are recited rather than enacted will require this form of sensorily rich language characteristic of the Experiential pole of PC1. The aria belongs at the Experiential pole of the distinction because, formally, it is a first person super narrative of sorts. In it, the singer sets out the chess pieces and then puts into motion to illustrate what has happened, might happen, or will happen.
Experiential example 3: H. Bate Dudley, Airs, Ballads…The Blackamoor Washed White (1776), tagged text, plain text.

The several airs in this text, once sung as part of a comic opera that included Sarah Siddons, express the vicissitudes of lovers as they progress toward nuptuals. The pastoral scene rendered by words such as “lyre,” “tree,” “skies,” and “beechen” (SenseObject, SenseProperty) make sense as part of the recital of plot events; but there is also sensory language being used to characterize the singer’s situation metaphorically — a schoolboy stealing sweet honey from a bee. The sensory language and (blue) Motions, then, are used not simply to communicate plot events that may not have been enacted on stage, but also to paint internal feelings by analogizing them to a sensory scene. The resources of (red) FirstPerson, which supports the sensitized reporting of actions, extend beyond a simple need to report events that advance a narrative; that language can also be used to strike an attitude toward plot developments by recasting them as another sensory scene.
Intersubjective example 1: Thomas Holcroft, Anna St. Ives (1792). Tagged text, plain text.

Anna St. Ives is the first British Jacobin novel; it was written by Thomas Holcroft. The narrator is describing an encounter with a Mr. Henley who is reluctant to begin a conversation about the narrator’s relationship with his daughter. Each of the two characters discloses something of his inner life; the entire exchange is related from the perspective of one person who both recounts and interprets it in (purple) FirstPerson. For example, the narrator wants the reader to know that he’s anxious for Mr. Henley to say what’s on his mind (“My own wish that he should be explicit was eager”), which then motivates the exchange from the standpoint of the narrator (“my own wish”). The meeting of minds in recounted dialogue is mediated through (red) SubjectivePercept words such as “dissuade,” “hesitated,” and “minds,” along with (blue) SelfDisclosure words (“my own”, “I desired”, “I think”.) In comparison with passages that exemplify the opposite pole of this pattern, these words mark the fact that the actions and pressures in the scene are internal to someone, not something. Autobiography features (green) register a character’s awareness of a life history (“I had”, “when I”), implying a subject whose past states and relationships (“my daughter”) are recallable in the present. (Autobiographical features imply a social, developmental subject.) As a representative of the Intersubjective pole, then, this passage from Holcroft depicts the inner life of one “me” making contact with another.
Intersubjective example 2: Samuel Richardson, Clarissa (1748). Tagged text, plain text.

In this passage from Richardson’s Clarissa, the eponymous narrator is telling Miss How about the hostile reception she received from her own family when she was called home from an earlier visit to Miss How’s house. In the recounted scene, Clarissa’s family forces her to justify the fact that she has been spending time in the presence of a Mr. Lovelace, her brother’s sworn enemy, while at the How residence. Clarissa must first narrate what happened in Miss How’s company and then state what her real intentions were, a move that forces her to alternate between (green) Autobiography (“I was”) and (blue) SelfDisclosure (“I would”). The alternation between “I was” and “I would” occurs frequently in the novel (twice in this passage); it demonstrates the narrator’s tendency to pivot between recollection of past events and vocalized reaction to those events. Words that imply judgments about, or interpretations of, a social situation — (red) SubjectivePercept (“like to have”, “even”, “voluntary”, “tacit”) — give insight into relationships among actors in a social situation. The abundance of accusative case “me” tagged as (purple) “FirstPerson”, moreover, mark the fact that the things being described are placed in relation to the narrator — to a narrating “me.” In using these features together, Richardson provides a rich view onto a consciousness that is both socially aware and able to render that awareness through recounted action.
Intersubjective example 3: Fanny Burney, Cecilia, vol. 3 (1782). Tagged text, plain text.

In this passage from Fanny Burney’s Cecilia, Cecilia and Mrs. Belfield discuss Cecelia’s interaction with Mrs. Belfield’s daughter, Henny. This passage provides another example of a “meeting of minds,” one in which a speaker (Mrs. Belfield) speculates on the intentions that informed “the little accident that happened when I saw you before,” when an “odd thing” (red SubjectivePercept) happened. The (green) Autobiographical features are necessary, even in small amounts, because Mrs. Belfield needs to relate a past event (“when I saw”) to the thinking she now unfolds, a sequence that discloses her own perspective on the story (“I mean to say”). Inevitably, that process is colored by subjective judgments (in red, “got the upper hand”, “just as well”) which are themselves anchored in the (purple) FirstPerson pronouns used by the quoted speaker.
Extrasubjective example 1: Edward Donovan, The Natural History of British Insects (1801). Tagged text, plain text.

Edward Donavan’s Natural History is the first example of the Extrasubjective pole of PC2, and illustrates the tendency to relate objects of experience without explicitly locating them in a particular consciousness; those objects are available to any person whatever, who in the case of these texts is the reader. As one might expect in a natural history text, there are plenty of declarative sentences. Here (red) Numbers are used to coordinate bibliographic sources (“Vol. 111”) and to coordinate reference points (“two others on oaks”), which has the effect of locating authority outside the narrator. SenseObject items (green) are picking out concrete things in the natural world (“Habitat,” “willows,” “moth,” “abdomen”). AbstractConcepts (blue) are abstract nouns (“species,” “English,” “country,” “descriptions”) as well as symbols (p.). The (purple) CommonAuthority phrase — “the general” — situates the quoted description outside the realm of private opinion, just as the “We” pulls the frame of authority outside of the embedded narrator. This passage is very much of a piece with the emerging rhetoric of the scientific report, hewing to Bishop Sprat’s rhetorical ideal (in his praise of the Royal Society) of trying to keep words tied to things.
Extrasubjective example 2: Decree, Charles by the Grace of God (1633). Tagged text; plain text.

This Extrasubjective passage differs from the first in that the decree relates official actions and information relevant to those actions; it exceeds the consciousness of any one narrator or individual because the affairs of state are by definition larger than any one person. The passage references only a few (green) SenseObjects (“penny”), and when it does, the writer uses it as a means of coordinating amounts of time and resources (years, pennies, Feast) with the authorities who control those resources (purple CommonAuthority words such as “Parliament,” “Sherrifs,” “regalities,” “Kingdom”). As is the case with many Royal decrees concerned with resources, amounts need to be spelled out so that they can be understood and honored, which is why there are so many (red) items tagged with Number.
Extrasubjective example 3: Robert Norman, A discourse on the variation of the cumpas (1581). Tagged text, plain text.

Robert Norman was a sixteenth century navigator who discovered magnetic inclination. In his 1581 Discourse on the compass, he reports observations that show variations along the horizontal plane of the magnetic needle. The highlighted passage shows, once again, the quick succession of (red) Numbers and (blue) AbstractConcepts — “variation,” “account,” and “observation” — words that refer to abstract relationships (differences in angles) or intellectual actions (observing, accounting). References to specific measurements that are the subject of argument are then anchored to a (green) SenseObject — the “Sun” — and an AbstractConcept (“Horizon”), both of which are the phenomenal supports for the abstract reasoning on display here. Norman’s Discourse illustrates the Extrasubjective pole of PC2 because the concepts it appeals to are the objects of geometric demonstration and so by definition not unique to the consciousness of an individual at a given moment. This is not to say that a living person did not observe the things related by Norman; presumably they were. The passage is Extrasubjective, however, because Norman’s manner of relating his observations shows them to be products of a mind whose interests arise from the interaction of physical objects and concepts, not the social relations of unique moral beings.
Distribution of Genres Across PC1 and PC2
We have focused in the foregoing analysis on the specific language (LATs) whose distribution suggests two places where the energy in the system lives, energy being a metaphor for significant correlations or dependencies among multiple features. PC1 and PC2 explain 7.1% and 5.2% of the variance in the corpus (respectively), providing a feature-based map of two powerful dynamics or oppositions that separate texts in the 1080 subcorpus. No act of human labeling contributed to the positioning of items in this space. In this section, we pause to ask how a set of independent interpretive judgments about literary genre might map onto the statistically derived PCA space discussed in the last section. Do genres fall out along lines that correspond to the axes as we have presented them?
The VEP project made this type of comparison possible, furnishing subcorpora that were labelled by domain experts according to recognized genres and subgenres. In the case of the 1080 Corpus, we are able to use a set of hand-curated labels for a chronologically balanced sub-set of the corpus.[2] All 1080 items are classified into 31 genre categories ranging from things such as “lists” to “drama” to “autobiography” to “narrative verse.” When we look at the mean score of those 31 genres on each of the two components, we find that 21 of the 31 groups of items score significantly higher or lower than the grand (group) mean on PCs 1 and 2. Two of the genres — “drama” and “lists” — had significantly higher or lower scores on two components at once, participating in two patterns simultaneously.[3] Below is a chart showing genres that fall significantly above or below the group mean on the two components:

And here, for reference, is a chart showing the LATs that correspond to each of the ends of the principal components:
We have several observations to offer on the these groupings of genres around the two axes. First, the groupings of human labeled groups along these axes make a certain amount of sense. It is not hard to accept that “legal decrees” are Abstract — that they use CommonAuthority words in sequences that specify logical, legal, or moral obligations. Nor is it surprising that texts characterized as “narrative verse” are full of FirsPerson words. It is also unsurprising that “fictional prose” and “drama” texts would be Intersubjective, while “science” and “medical” texts are Extrasubjective. (Links to sample texts, labeled by genre and classed according to the four poles, can be found in an Appendix below.) There is, then, some intuitive overlap between the statistical oppositions and the arrangement of texts across those oppositions by genre.
We also observe that verse forms of all kinds, regardless of subject, tend toward the Experiential pole. Even when the subject matter is largely the same — as with “religious verse” and “religious prose” — the use of verse throws an item to the Experiential side of PC1. It is not surprising to learn that early modern verse is full of images and is expressive (anchored in the first person). But it is interesting to see a close link between verse forms of all kinds and sensory language. That pairing tells us that, even when verse is relating concepts or interior states of mind, it reaches for sensuous objects and events in order to render them. Verse does not prosecute an argument; rather, it sets things out for a reader to experience.
A third observation deals with narrative, which spans both sides of the continuum of PC2. Fictional prose, drama, and autobiography are all narrative forms. They favor the Intersubjective pole. But history and nonfictional prose also rely on narrative sequence, and they are Extrasubjective. The fact that narrative spans both ends of PC2 suggests that narrative sequence can be used to accomplish two pragmatically different tasks — relating interpersonal events in the social world (Intersubjective), or relating events that have a purely physical or “historic” and so impersonal character (Extrasubjective). The distinction represented by PC2, then, seems more basic than any distinction we might propose between texts that employ narrative sequence and those that do not.
A final observation deals with the fact that so few genres score significantly higher or lower on both principal components. This is the case only with lists and drama, both of which are formally rigid in ways that perhaps other texts in the corpus are not. Leaving stage directions aside, drama texts consist entirely of speeches in the first person, whereas lists are table-like and are meant to be scanned discontinuously as well as read serially. It is not clear why two of the most formally constrained types of text in the subcorpus participate in both patterns whereas others participate in only one. It makes sense, however, that plays would be an extreme version of the mixture of Experiential and Intersubjective, while lists are a stark combination of the Extrasubjective and Experiential. The advantage of having a map of the whole space is that an item in one quadrant can be related to all the others. Drama is drama, for example, because it is not Abstract and not Extrasubjective (in the way we have been using these terms). Descriptions of sets of items, then, can be positioned within a larger cultural field.
Texts in Four Quadrants: A Combinatory Look at Text Types
As the prior section suggests, the corners of our PCA plot are worth interpreting as regions where two independent patterns intersect. We have chosen to name these quadrants where items are participating in two patterns at once and thus contain both sets of distinguishing LATs while lacking both sets belonging to the opposite corner. Our interpretation of the items in these corners, based on an inspection of the texts themselves, yields the following diagram in which corners represent distinctive combinations:

[PCA plot of 1080 corpus with as subset of selected items highlighted in the “corners” where a text participates in both patterns. Corner regions are labeled.]
We characterize the corners of this PCA in terms of the stance or actions they take. Those actions can be “Urging” (Abstract and Intersubjective), “Explaining” (Abstract and Extrasubjective), “Describing” (Experiential and Extrasubjective), and “Imagining” (Experiential and Intersubjective). After surveying examples in each, we discuss the significance of this fourfold division for our thinking about early modern texts and ask how these labels are different from the genre or period labels we usually use to talk about texts in groups. Selected items that participate in two patterns at once are highlighted with a different colors. In a subsequent section, those selections and corresponding colors will “carry over” into a projection of the entire corpus.
Urging. Beginning at the upper right hand corner of the plot, texts we identify as “Urging” tend make arguments, engaging the reader agonistically from a bounded point of view. (Rhetorically, they rely on both logos and ethos.) Three texts that represent “Urging” are found below, with LATs contributing to their location highlighted:

George Berkeley, A defense of free thinking in mathematics… (1735), tagged text
Jean Calvin, Sermons… (1560), tagged text
George Halifax, Some cautions offered (1695), tagged text
Explaining. Unlike “Urging” texts, “Explaining” texts locate their own authority in objects or impersonal concepts rather than an individual. Texts in this quarter tend to be scientific writings or legal decrees and proclamations — texts in which an impersonal authority or method (geometry, empiricism, theology, the crown) is making the connections between entities encountered by the reader.

Thomas Hobbes, Elements of philosophy (1565), tagged text
Benjamin Robins, A discourse concerning the nature of Newton’s method… (1735), tagged text
Charles Hutton, The force of fired gunpowder… (1778), tagged text
Describing. “Describing” texts tend to be more inert rhetorically, enumerating physical events and objects rather than subsuming them under organizing concepts. Texts in this quarter include natural histories and lists (location surveys, catalogues of military equipment, geographical antiquities), which tend to be dialectically unstructured. A cluster of Latin texts can be found in the lower left, placed there because of the high degree of “AbstractConcept” words that Docuscope recognizes in them.

Hannah Woolley, The queen-like closet…of rare Receipts (1670), tagged text
Thomas Chaloner, A short discourse of…Nitre (1584), tagged text
Cornelis Antoniszoon, The safegard of sailors or…common navigations (1605), tagged text
Imagining. Texts that “Imagine” are mostly fiction. Plays, burlettas, and operas are located almost exclusively in this quarter. This clustering of fictional genres in the space is perhaps unsurprising, since each of these genres is a mix of the Intersubjective and Experiential tendencies surveyed above, including the tendency to first person pronouns (in spoken dialogue) and the abundance of physical detail (essential when not all action can be shown):

Susanna Centlivre, A wife well managed… (1715), tagged text, plain text
J. G. Holman, Abroad at home: a comic opera… (1796), tagged text, plain text
Isaac Bickerstaff, Love in a village (1763), tagged text, plain text
To review before moving to the next section, we have used a nonsupervised statistical technique to call attention to language (LATs) that can help us describe dependencies we see in the corpus. Having identified two basic patterns — Abstract/Experiential, Intersubjective/Extrasubjective — we have shown how these patterns can be used to sort genres derived independently by human study and expertise. The distribution of the human labeled items according to genre made intuitive sense when plotted according to the patterns (PCs 1 and 2) arrived at independently by nonsupervised means. Returning to those two initial patterns, then, we explored the corpus in terms of combinations of each, defining four rhetorical tendencies in the corpus: “Urging,” “Explaining,” “Describing,” and “Imagining.” We now discuss how this interpretation of the corners of the PCA plot for 1080 texts might help us understand the dynamics of the full TCP corpus.
1080 Versus the TCP Corpus, Dynamics Across Time in the TCP
The principal components used to provide insight into the 1080 corpus also capture patterns that hold for all the texts in the TCP corpus. To demonstrate this, we have taken a plot of the 1080 PCA scatterplot, highlighting by color items in the corners, and retained those color codings for a PCA biplot that is now built on the full corpus. While the order of components shifted — the Intersubjective/Extrasubjective is now the first principal component rather than the second — the loading of LATs on both components is almost identical. One can have a visual intuition into the scaling of this pattern in the following diagram, which compares the position of items in the corners of the 1080 corpus scatterplot and preserves their color designation in a PCA scatterplot of the nearly 61K items in the full corpus:

While some of the loadings have shifted, rotating the pattern clockwise slightly, the original highlighted items still distribute into recognizably orthogonal sectors. The overall pattern persists.[4] We can note here that the shift in rotation and in the order of components is due to the fact that the 1080 corpus randomly sampled 40 items from each decade spanning 1530-1799, which gave a greater weight to decades with fewer items and reduced the weight of items in decades with more titles. The PCA plot at right captures all texts in every decade, which results in a stronger opposition between Intersubjective and Extrasubjective texts. But the overall set of oppositions remains the same; the positions of the “Imagining” and “Urging” corners have flipped.
Having shown that the components are interpretable, we can discuss their movements as they fluctuate decade by decade. Recall that PC1 defines the Intersubjective/Extrasubjective opposition, while PC2 defines the Abstract/Experiential opposition. Here are the means and standard deviation measurements of those components by decade:

What becomes clear immediately is that the corpus is unevenly curated. Some of the major time shifts in components are caused by different mixes of texts that were transcribed based on the underlying bibliographies — Pollard and Redgrave STC 1, Thomason Tracts, Wing’s STC 2, ECCO, Evans. These bibliographies cover different periods within the overall sequence of 1420-1820. Within each decade, for example, survival rates will differ based on whether that decade is early or late in the sequence. Selection principles governing which items within those constituent bibliographies were transcribed into the TCP are also inconsistent. And in at least one instance (Thomason Tracts), texts survived because an individual made a concerted effort to collect and save certain types of materials.
Looking at the period from 1640-1699, we see that these decades contain many more items than the prior decades, evidenced by the smaller standard deviation bands surrounding the mean measures during this period. This change is due partly to historical events, since the English Civil War led to a profusion of political pamphlets, and so, a larger number of discrete documents that could be transcribed and measured. The change in the number and types of texts captured during this period also reflects that fact that political tracts from the period were systematically collected by a printer named Thomason. These “Thomason Tracts” (1640-1661) were transcribed as part of the EEBO-TCP project, and so represent a distinct curatorial tradition and bibliographical source. Major shifts in measurements on the principal components occur in these two decades (discussed below), after which point the corpus represents mainly items from the Wing STC catalogue (1641-1700), which does not favor political tracts and is comprehensive. Beginning in 1700, the corpus transitions to items drawn from the ECCO-TCP project (Eighteenth Century Collections Online) and items from Evans (early American literature).[5] The coverage and generic range of titles decreases suddenly in 1700, which we see in the pronounced shifts in PCs 1 and 2 at this point.
Differences in curation cannot be the only factor at work in these time based shifts, however. Around 90% of the available unique titles printed during 1475-1700 were transcribed for the TCP. If the contributing bibliographies were reasonably comprehensive, then at least some of the movement we see during these years is due to underlying cultural factors. The transition between the 1630s and the 1640s for example — bibliographically, from Pollard and Redgrave’s Short Title Catalogue to Thomason and Wing — is culturally significant because it marks the transition to open military hostilities connected with the Civil War. In the 1640s, for example, we see a sharp movement toward the Abstract and Extrasubjective patterns described above. Taken together, these shifts move texts toward the “Explaining” quarter of our map. There might be historical reasons for such a movement: the response to the Civil War in print was, in effect, to litigate the conflict through declarations and decrees, particularly in the first decade of 1640-49. The Licensing Order of 1643 effectively made Parliament a censor for print publications, and this ongoing censorship would have narrowed the range of what was published. That shift is quite visible in the plot above.
During the second decade of the conflict (1650-59), texts remain at an all time high for their measurement on the Abstract pattern (PC2), but now they are more Intersubjective (rising PC2), suggesting movement toward the “Urging” corner in the PCA plot. A crude interpretation of this sequence of shifts would be that civil conflicts occurring in the earlier decade (1640-49) needed to be defended “legalistically” in print — essentially, an explaining task. From 1650-59, however, arguments appear to become more subjective, grounded in moral exhortation rather than impersonal decrees. The regicidal sequence, one might say, begins with explanation, and ends with exhortation.
The sudden rise in explanation following a political upheaval returns in the immediate aftermath of the Revolution of 1688, when once again we see a shift toward “Explaining” (falling PC1 toward the extrasubjective; rising PC2 toward the abstract) during the decade 1690-99. Here we may be seeing the effects of the expiration of the Licensing Order in 1694, which allows a greater diversity of items into print once Parliamentary control lapses. The shift might also reflect changes in political and cultural climate that follows the installation of William and Mary in 1689, a “bloodless” revolution that would have to be explained procedurally in print.
A second noteworthy movement occurs at the beginning of the eighteenth century, just as the TCP corpus begins to be populated by a mix of American items (from Evans) and the texts gathered in ECCO. Here the change in inclusion criteria helps us account for the dramatic shifts in PCs 1 and 2, since only certain items from a much larger possible corpus were transcribed. Beginning in 1700, we wee a sharp movement toward the “Imagining” quarter of the PCA space, with texts becoming simultaneously more Intersubjective and Experiential. Some of this pattern must be explained by the tendency to include famous works of fiction in the corpus by its creators and sponsors. But this period also coincides with the rise of the epistolary novel and fictional prose, forms that regularly relate lived action through the bounded perspective of social beings. The rise in this pattern may thus also reflect the increasing presence (and cultural success) of the novel over the course of the eighteenth century. That source is being added to the “signal,” even if we may not be seeing the full spectrum of printed texts from the period.
Toward the end of the eighteenth century, the TCP texts retain a high level of Intersubjectivity with respect to earlier decades in the corpus, but become even more Experiential (i.e, the movement of PC2 in red continues down). By 1799, TCP texts are more likely to express the values and judgment of an individual speaker, but are also much more likely to express those judgments with respect to physical objects and actions in the world. The textual world in this part of our sample is perhaps more clearly one of social experience; actions following each other causally as in a story or experimental trial, rather than concepts enumerated in sequence (first, second, third) as they would be in a more abstract presentation.
Language stressing causes, effects, and consequences appears to increase over the course of the eighteenth century, reflecting perhaps an empiricism now being expressed in medical texts, natural philosophy, and psychology (also increasingly present in the corpus). Decade by decade measurements of a LAT called Consequence — a LAT that tags phrases such as “an effect of”, “in consequence of,” “resulting from” — suggest how this type of writing and thinking is manifesting itself in print:

Manual inspection of those texts scoring high on this measure throughout the eighteenth century shows them to be practical texts about medicine, the human body, and human conduct (often warning of the connection between conduct and ailments).[6] A detailed study with new genre metadata might confirm or disprove the hypothesis that a strain of Consequence-rich writing is connected to science and the practical focus of American publishing, both of which figure prominently in the texts selected for transcription within these decades. Fictional prose texts — the newcomer on the scene in terms of imaginative writing — may also use this feature more than drama, its imaginative predecessor. It is equally possible that the rise in Consequence language simply reflects the fact that this LAT counts later expressions of causal or consequential thinking, whereas earlier instances go uncounted.
Conclusion
We have shown that we can apply what we learned from a small part of the TCP to the entire corpus, even when metadata for the whole does not exist. Part of this work was interpretive; we characterized and named the patterns PCA found in the smaller corpus after exploring relevant features in example texts. The work was also confirmatory. When we introduced genre labels produced independently (via reading) into a feature space derived from PCA, genres distributed intelligibly across that space. Our final task was to see if this “map” could be understood in light of bibliographical traditions and historical events. We saw, first, the effects of uneven corpus curation and competing bibliographic traditions in decade by decade comparisons. We also noted the possible effects of large scale political, intellectual and cultural shifts — the Licensing Act of 1643, the English Civil War and Revolution of 1688; the rise of science and “practical” writing; the development of imaginative prose fiction in the epistolary novel.
If cultural effects can indeed be seen with the aid of quantitative proxies, we should acknowledge that there is a pragmatic side to communicating in print that is by nature repeatable, but also adaptable. As the literary critic I. A. Richards argued almost a century ago, texts have particular means they use to create their effects within readers, and those means are stable enough to study. It is no accident that few writers in the seventeenth century choose to publish lists of military assets in the form of a dialogue, or that legal proclamations were not set in blank verse. Such choices would be impractical in the Richardsonian sense.[7] That is not to say they are impossible choices. But they rarely happen.
When, on the other hand, a writer chooses what seems to us an unusual strategy — say, when Margaret Cavendish decides to convey metaphysical truths about nature in a verse romance, as she does in Natures picture drawn by fancies pencil (1671) — we can begin to understand her novelty or lack of novelty as a writer, doing so with an actionable vocabulary we could never have created through selected reading.

[Caption: PCA plot of 61K items with two texts by Margaret Cavendish highlighted. Natures picture drawn by fancies pencil (1671) sits, predictably, in the Imaginative quadrant of the map, whereas Observations on experimental philosophy (1666), which includes The Blazing World, sits in the “Urging” quarter, showing differences in textual features and location for a single writer.]
Individual writers employ strategies from different regions of the map, and those differences suggest the constrained diversity of approaches they bring to making meaning. It also speaks to the diversity of concerns driving them to write. Milton and Defoe, for example, produced texts that distribute in different corners of the PCA map. Shakespeare did not.
The story of individual writers is one of greater and lesser variation, but the story of the corpus is one of stability and sameness. Early modern writers and publishers do certain things predictably, something we already knew, but that we can now describe more richly “at the level of the sentence.” Predictability is a function of constraints, some of which apply consistently, some of which loosen over time. Ideologies, for example, are slow to change. Biological limits to human attention are real and change with evolutionary pressures. Most economic and political practices transcend generations. These forces go to work on any act of composition, publication, and even consumption of print; they cannot be dodged. There should, then, be some stability and predictability on the level of the whole, which is what we believe we are seeing here.
But constraints do shift, a fact that can be grasped with the study of many more texts than anyone can read. We have tried to create markers for such changes, and to offer interpretations (“urging,” “explaining”) that link those markers to bibliographic traditions and to changes in early modern cultural life (wars, literary fashions).[8] Getting to this point required us to build patterns from the ground up, first from unsupervised statistical analysis, then from contextual, sentence-level interpretation of examples. Now that the corpus is at least minimally interpretable, we do not believe the resulting map and its directions will change significantly. Others can interpret the patterns and the events they correspond to differently, but on a certain level, the findings we present here are descriptive. Certain words and phrases are used more often in the absence of others. Certain periods of time favor different distributions of those patterns. That story is in the numbers. But someone has to look at those words, give a name to those patterns, and explain what they might be accomplishing. We see the latter as the main contribution of this study. Any number of obstacles present themselves to scholars trying to do such work, but we hope we have surmounted at least some of them with the tools available to us.
Appendix: Sample texts from 1080 corpus, labeled by genre, and grouped according to favored poles of PCs 1 and 2.
Items from genres that score high on the Abstract pole of PC1 include:
Balthazar Gerbier, To the honorable… (1646), tagged text (argument)
Daniel Defoe, An enquiry into the danger… (1712), tagged text (argument)
A proclamation that strangers… (1539), tagged text (legal decree)
A declaration of the lords… (1642), tagged text (legal decree)
Thomas Walcot, The Trial of Capt. Thomas… (1683), tagged text (legal prose)
Thomas Pain[e], Definition of a Constitution… (1791), tagged text (legal prose)
Niccolo Machiavelli, Machivael’s [sic] discourses… (1663), tagged text (nonfictional prose)
Oliver Goldsmith, An enquiry into the present… (1759), tagged text (nonfictional prose)
Cicero, Those five questions… (1561), tagged text (philosophy)
Adam Smith, The theory of moral sentiments… (1759), tagged text (philosophy)
Philipp Melanchthon, The confession of the faith… (1536), tagged text (religious prose)
William Penn, A key opening a way… (1693), tagged text (religious prose)
William Fulke, A sermon preached… (1571), tagged text (sermon)
George Keith, A sermon preached… (1700), tagged text (semon)
Items from genres that score high on the Experiential pole of PC1 include:
Richard Tarlton, A pretty new ballad… (1592), tagged text (ballad)
A lover’s complaint… (1615), tagged text (ballad)
William Shakespeare, The merry wives… (1630), tagged text (drama)
Susanna Centlivre, The wonder: a woman keeps… (1714), tagged text (drama)
William Drummond, Tears on the death of Meliades… (1613), tagged text (elegy)
Thomas Holcroft, Elegies… (1777), tagged text (elegy)
An extraordinary collection… (1693), tagged text (list)
Thomas Gray, A supplement to the tour… (1787), tagged text (list)
Alexander Mongtomerie, The cherrie and the slaye… (1597), tagged text (narrative verse)
Henry Carey, The grumbletonians… (1727), tagged text (narrative verse)
John Lyly, A whip for an ape… (1589), tagged text (poetry)
Alexander Pope, Eloisa to Abelard… (1719), tagged text (poetry)
Matthew Parker, The whole Psalter…(1567), tagged text (religious verse)
Philip Doddridge, Hymns founded on various texts (1755), tagged text (religious verse)
Alexander Craig, The amorose song… (1606), tagged text (verse collection)
Hannah Cowley, The poetry of Anna Matilda (1788), tagged text (verse collection)
Items from genres that score high on the Intersubjective side of PC2 include:
Charlotte Charke, A narrarive of the life… (1755), tagged text (autobiography)
Laetitia Pilkington, Memoirs… (1748), tagged text (autobiography)
William Shakespeare, The merry wives… (1630), tagged text (drama)
Susanna Centlivre, The wonder: a woman keeps… (1714), tagged text (drama)
Samuel Richardson, Pamela… (1741), tagged text (fictional prose)
Fanny Burney, Cecelia… (1782), tagged text (fictional prose)
Items from genres that score high on the Extrasubjective side of PC2 include:
John Smith, An accidence…. (1626), tagged text (education)
Charles Mowet, A direction to the husbandman… (1634), tagged text (education)
Jachim Camararius, [The history of strange wonders], (1561), tagged text (history)
Edmund Burke, A short account… (1766), tagged text (history)
An extraordinary collection… (1693), tagged text (list)
Thomas Gray, A supplement to the tour… (1787), tagged text (list)
Thomas Chaloner, A short discourse… (1584), tagged text (medicine)
Robert Boil [Boyle], Medicinal experiments… (1692), tagged text (medicine)
Henry Chettle, A true bill…(1603), tagged text (nonfictional prose)
Kinki Abenezrah, An everlasting prognostication… (1625), tagged text (nonfictional prose)
Church of England, Articles to be enquired… (1554), tagged text (religious decree)
Church of England, Orders set down… (1629), tagged text (religious decree)
Robert Norman, The new attractive… (1581), tagged text (science)
Oliver Goldsmith, An history of the earth… (1774), tagged text (science)
-
The VEP project created an implementation of Docuscope that can be used as an online utility with user supplied texts; it also supplied pre-computed LAT percentage counts for all TCP texts, using a spelling standardized, SimpleText corpus. ↑
-
On the creation of the 1080 subcorpus, see http://graphics.cs.wisc.edu/WP/vep/vep-early-modern-1080/. The genre labels used here were the precursor to those deployed in the VEP 1080 subcorpus; they are not available for download on the VEP site. We have made them available via our master .csv file. ↑
-
Note that there are other ways to establish the sorting power of the principal components against received genres. The decision limit for our analysis of means (ANOM) was 0.05. ↑
-
The persistence of that pattern should not be surprising if the 1080 sample is a close to random sample of the full corpus. ↑
-
The EEBO portion of the corpus covered 90% of the available unique titles, with a principled exclusion of only a few classes of items — illegible, largely non-textual (pictures, music, math), largely numeric (most almanacs, which also tended to the illegible), and largely non-English (this excluding many large expensive works like multilingual dictionaries and the Walton Polyglot. ECCO-TCP texts (eighteenth century), on the other hand, tended to favor authors whose works straddled the 17th and 18th centuries. Individual ECCO-TCP partners also requested particular items — medical texts, and works of fiction with Irish connections. About a third of the Evans texts (early American) were transcribed and so added to the TCP corpus based on recommendations of “important” works by the American Antiquarian Society. This account of the contents of the TCP was provided by Paul Schaffner, whose assistance the authors gratefully acknowledge. ↑
-
The frequent presence of medical texts post 1800, transcribed at the request of some of the TCP institutions, is clearly affecting this measurement. ↑
-
I.A. Richards, Practical Criticism (London: Kegan Paul, 1930). See also Sharon Marcus and Stephen Best, “Surface Reading: In Introduction,” Representations 108(1): 1-21. ↑
-
We have, in other words, taken a bounded set of features and made them proxies for constraining historical events or developments (cataloguing variations, differing object survival rates, genre developments, political upheaval). On the feature/proxy distinction, see Michael Witmore, “Latour, The Digital Humanities, and the Divided Kingdom of Knowledge,” DOI: 10.1353/nlh.2016.0018. ↑
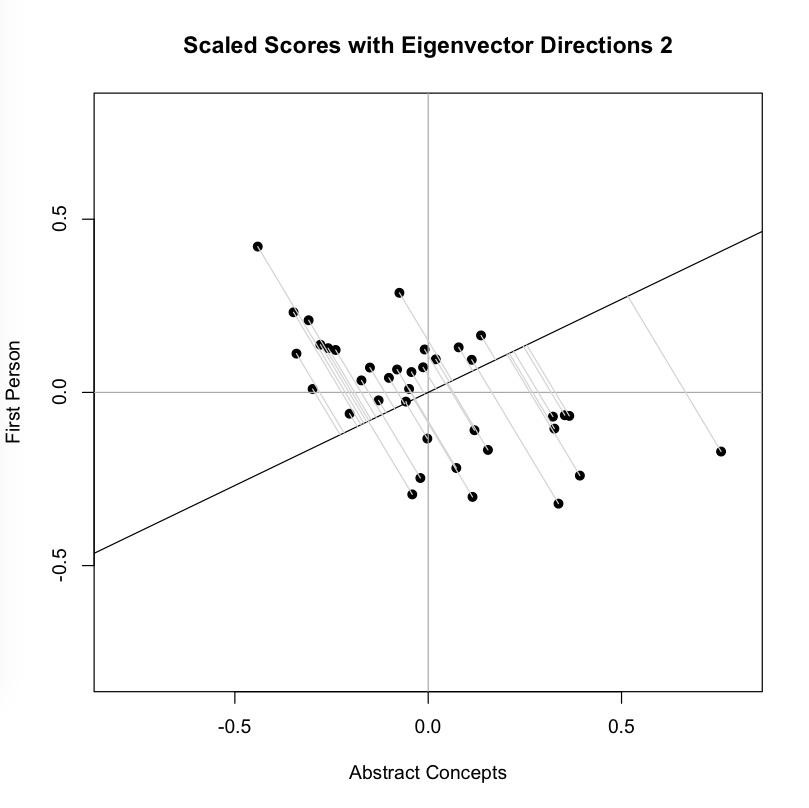
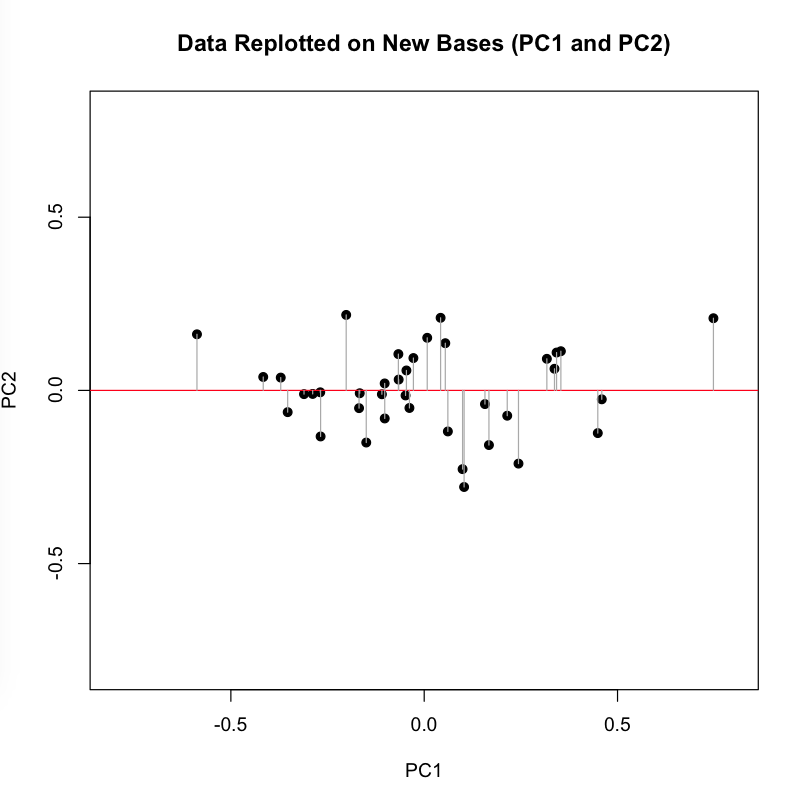
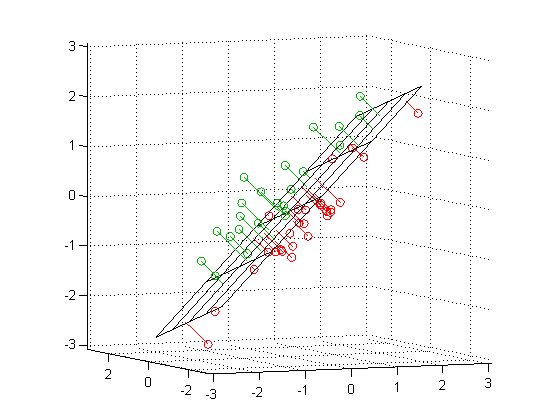
 Plotting the items in two dimensions gives the viewer some general sense of the shape of the data. “There are more items here, less there.” But when it comes to thinking about distances between texts, we often measure straight across, favoring either a simple line linking two items or a line that links the perceived centers of groups.
Plotting the items in two dimensions gives the viewer some general sense of the shape of the data. “There are more items here, less there.” But when it comes to thinking about distances between texts, we often measure straight across, favoring either a simple line linking two items or a line that links the perceived centers of groups.
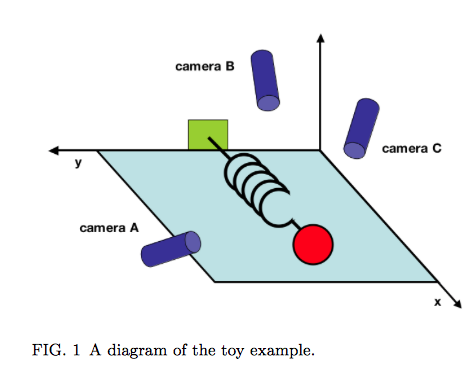
 To get started, you must place the
To get started, you must place the 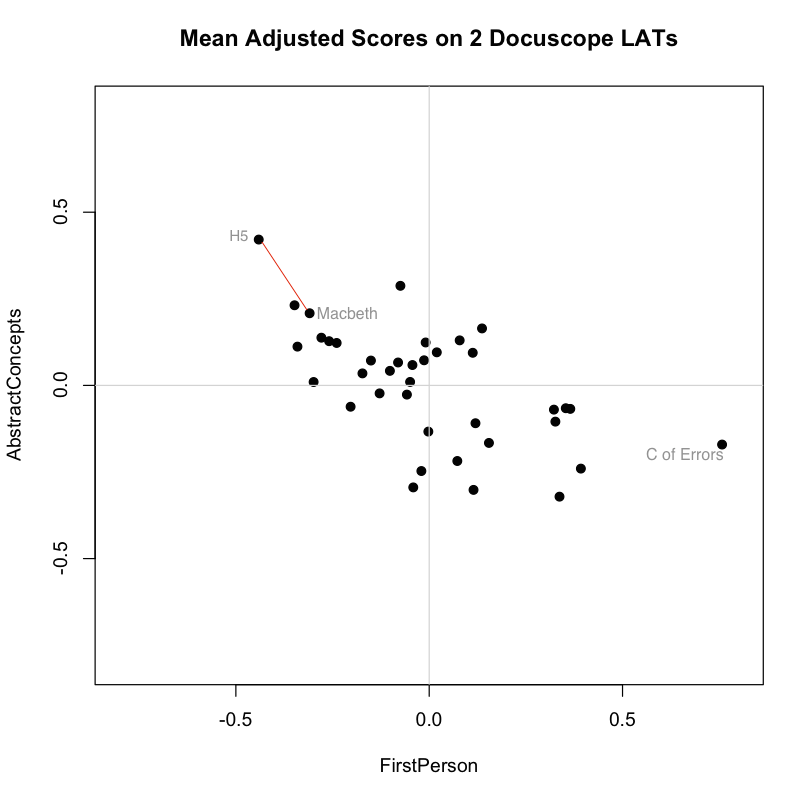
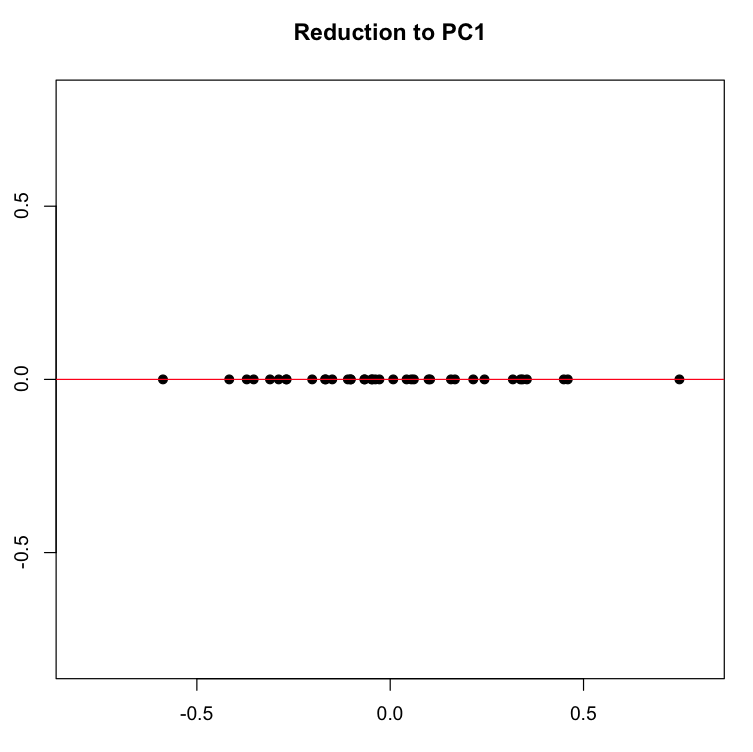
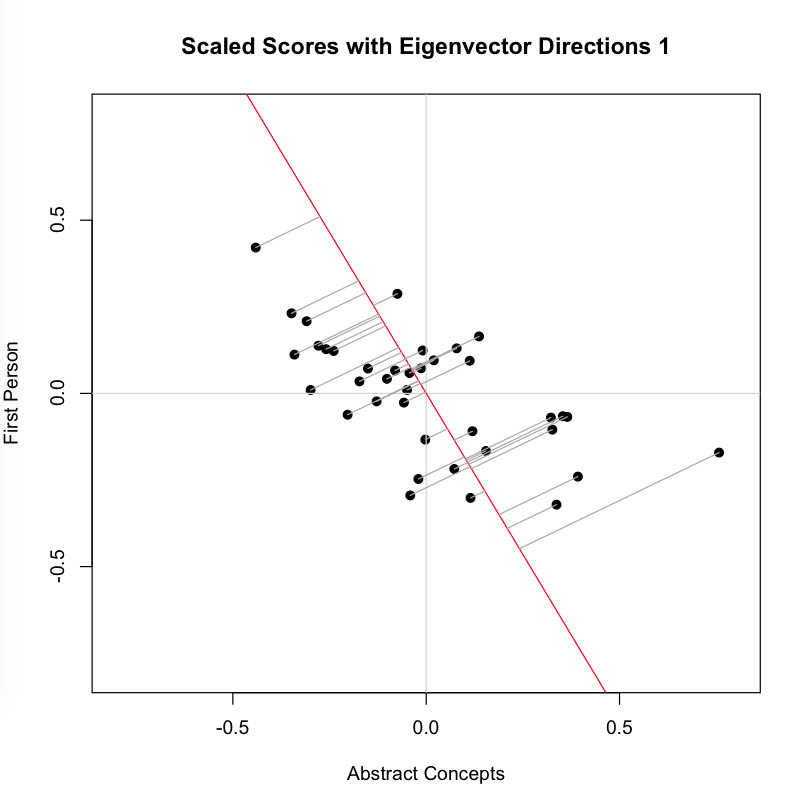 You can see that each point is projected orthogonally on to this new line, which will become the new basis or first principal component once the rotation has occurred. This maximum is calculated by summing the squared distances of each the perpendicular intersection point (where gray meets red) from the mean value at the center of the graph. This red line is like the single camera that would “replace,” as it were, the haphazardly placed cameras in Shlens’s toy example. If we agree with the assumptions made by PCA, we infer that this axis represents the main dynamic in the system, a key “angle” from which we can view that dynamic at work.
You can see that each point is projected orthogonally on to this new line, which will become the new basis or first principal component once the rotation has occurred. This maximum is calculated by summing the squared distances of each the perpendicular intersection point (where gray meets red) from the mean value at the center of the graph. This red line is like the single camera that would “replace,” as it were, the haphazardly placed cameras in Shlens’s toy example. If we agree with the assumptions made by PCA, we infer that this axis represents the main dynamic in the system, a key “angle” from which we can view that dynamic at work.