forthcoming papers on the material presented in this section of the talk:
Anupam Basu, Jonathan Hope, and Michael Witmore, ‘Networks and Communities in the Early Modern Theatre’, in Roger Sell and Anthony Johnson (eds), Community-making in Early Stuart Theatres: Stage and Audience (Ashgate)
Michael Witmore, Jonathan Hope, and Michael Gleicher, ‘Digital Approaches to the Language of Shakespearean Tragedy’, in Michael Neill and David Schalkwyk (eds), The Oxford Handbook of Shakespearean Tragedy (Blackwell)
Goldstone, Andrew, and Ted Underwood, 2014, ‘The Quiet Transformations of Literary Studies: What Thirteen Thousand Scholars Could Tell Us’, New Literary Historyhttps://www.ideals.illinois.edu/handle/2142/49323
The previous two posts explored how an eighteenth century novel uses words from an associated topic to fulfill, and perhaps shape, the expectations of an audience looking to immerse themselves in a life as it is lived. In this post I want to think a little more about the idea that the red words identified by Serendip’s topic model do something exclusively “novel-like” and that the blue words are exclusively “philosophical.” Both sets of words seem, rather, to aim at a common target, since each contributes something distinctive to the common project of rendering a moral perspective on lived experience. I want to caution against thinking of these topics as “signatures” of different genres; they may instead index narrative strategies that criss-cross different types of writing.
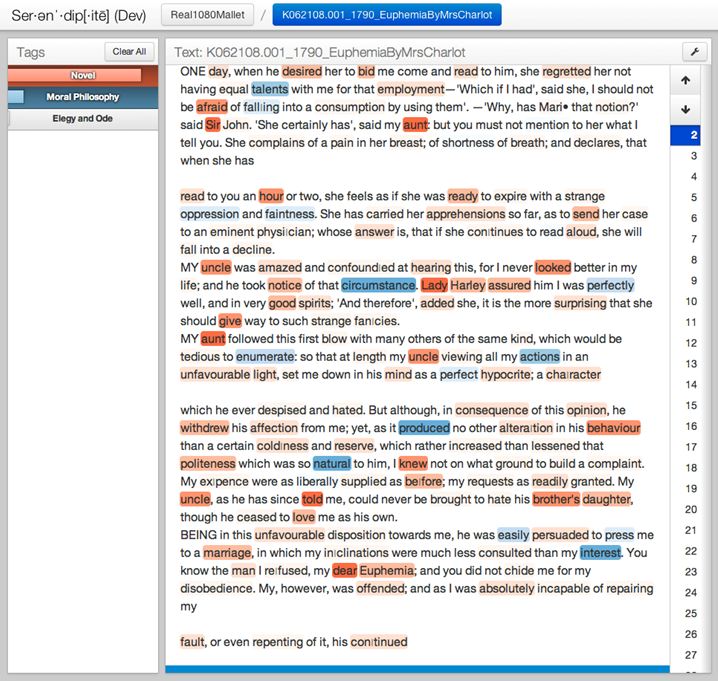
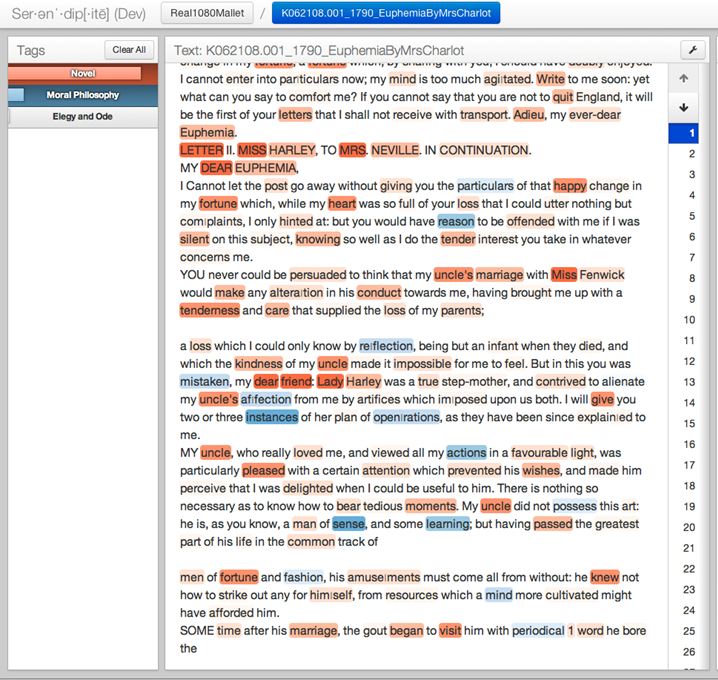
Take, for example, the passage from Lennox’s Euphemia that appears toward the bottom of the screen shot below:
After relating several details about her relationship with her aunt and uncle, Maria concludes: “BEING in this unfavourable disposition towards me, he [Sir John] was easily persuaded to press me to a marriage, in which my in|clinations were much less consulted than my interests.” This sentence illustrates some of the dynamics that Park described in her earlier post. On the one hand, Maria’s letter immerses the reader in a scene from life, rendering vivid the circumstances that led her uncle to make a fateful decision about Maria’s marriage prospects. Yet at the same time, the narrator dips frequently into the vocabulary of a more removed and somewhat static moral judgment – one that appraises “circumstance” in relation to “actions” and “interest.” The red words, novelistic in our analysis, are the words that show us how something happened: Maria’s uncle Sir John decided to force her into “marriage,” ignoring his niece’s wishes or inclinations because he was in an “unfavourable” disposition that made him more easily “persuaded” to this course of action. (We are getting contextual details – backstory – that make his decision intelligible.) These red, novelistic topic words – marriage, persuaded, unfavorable – are thus necessary for rendering the sequence of events that prompted her change of fortunes. A man was persuaded, his favor had changed, and a marriage ensued.
But the narrative sequence opens up onto a more general possibility for analysis. An abstract noun – “interest” – is offered as the nominal criterion for her uncle’s decision, but in the context of the sentence it seems to gloss the uncle’s reasoning as he might represent it to Maria (“this marriage is in your interest”), not the narrator’s feelings about that reasoning (“it was in my interest”). What we are getting, then, is the narrator’s view of how her uncle made his decision, what circumstances contributed to his thinking, even the abstract concept that he could have invoked in the absence of any residual “natural” sympathy for his niece’s inclinations. One sees, perhaps, a tension between the kinds of abstract nouns that appear in works of moral philosophy – in the screen shot above, “natural” “actions” “circumstance” “interest” – and the concrete terms of relation that render action for us in a more vivid, immediate way.
What is interesting about this passage is that it shows us how flexible the abstract vocabulary of moral philosophy can be when it is introduced into the narrative stream of a novel. In the passage above, Maria tells us that her aunt, Lady Harley, was stung by jealousy when she witnessed Sir John’s pleasure at hearing his niece read. Out of spite, the aunt insinuates that there is a contradiction between the “oppression and faintness” that Maria purportedly has complained of and her manifestly good spirits, which Sir John would otherwise take on face value. Maria then uses the abstract noun “circumstance” to characterize the fact of her good spirits, a fact which Sir John is now (culpably) discounting.
The shift in register becomes necessary because Sir John has abandoned his natural sympathy for Maria and is instead bringing a quasi-judicial process of weighing her actions (thinking “circumstantially”). It’s the intermixture of these fragments of moral reasoning with images of life as it unfolds – a didactic mix of abstract nouns and personal actions – that are allowing Lennox to stage distinct layers of sympathy and indifference, serving them all up for the reader’s observation. The shift to moral evaluation is even more decisive in the following passage from letter V, in which Maria tells Euphemia how Sir James came to doubt her aunt’s deprecations and once again view his niece in a favorable light:
Maria is moving into the realm of generalization (“I have often observed…”), and this shift requires the writer to “investigate” the ways in which Sir James was led to “compare” Maria’s behavior with a secondhand “picture” that has been drawn of her “disposition” by her aunt. These blue words might be seen as pivots in a process of moral judgment – the same process that the novel’s reader had to employ in evaluating Sir James’ earlier souring on his niece. Because this process itself is now the subject of narration, it is not surprising that the vocabulary needs to be more structured and abstract.
In using Serendip to explore how Euphemia behaves linguistically qua novel, then, we must start with the idea that novels mix the vocabularies of these two topics in order to layer points of view and to involve the reader, experientially, in a world where actions have moral significance. Moral philosophy words (blue) are important because they mark occasions where that state of experiential immersion has been temporarily deflected onto some explicitly moralizing, explicitly generalizing consciousness, a consciousness which may or may not be that of the narrator. Regardless of its origin, the capacity of that consciousness to withdraw temporarily from the particulars of the narrative and to render judgment on a kind of act seems a crucial aspect of the novel’s program, which Julie Park described in her previous post in terms of the novel’s epistolarity and emphasis on sensibility.
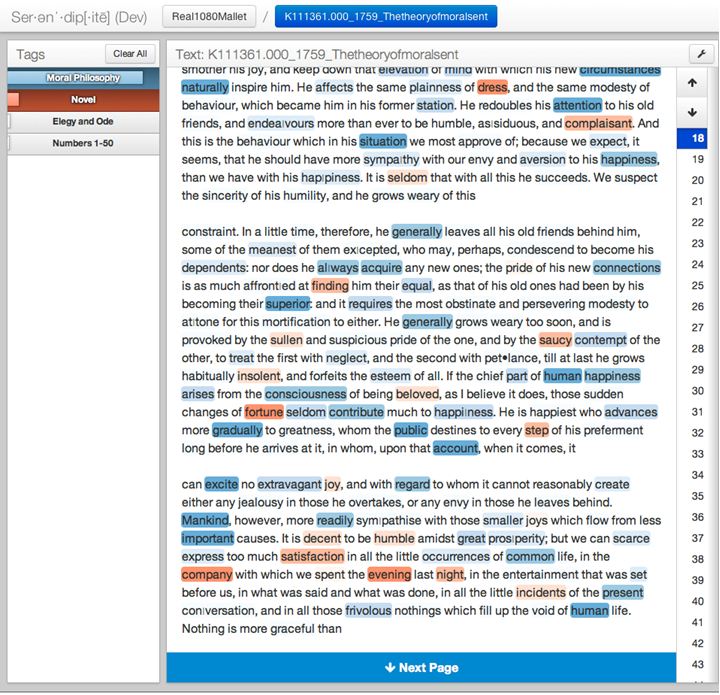
We can say, moreover, that this procedure of mixing words from these two topics also occurs in formal works of moral philosophy. Consider the passage from Smith’s Theory of Moral Sentiments below:
In this passage, Smith is describing the way in which a man – any man whatever – will alter his treatment of his friends if suddenly elevated in social status. Such a man becomes insolent and petulant, which is why Smith believes that one should slow one’s social rise whenever possible. “He is happiest,” Smith writes, “who advances more gradually to greatness, whom the public destines to every step of his preferment long before he arrives at it…” Smith is encouraging his audience to pass judgment on a drama whose characters are never rendered concrete, characters whose actions illustrate a concept. The closest Smith gets to a novelistic treatment of the life world occurs just after he has presented his maxim above. Instead of calculating and re-calculating one’s standing among friends, Smith writes, one should find “satisfaction in all the little occurrences of common life, in the company with which we spent the evening last night.” Smith modulates into the red here, drawing words from the life world as if he himself is reporting on events in his own life just the night before, events which ground and so justify the moral pleasure he takes in them precisely because they are not bloodless and calculating. Smith has, for a sentence or two, become an epistolary novelist, and it is this sudden (and relatively rare) excursion into the every day – the world of “last night” – that allows him to show the difference between happiness and its opposite.
As an excursion, this passage has to be brief. There is “a lot of blue” in moral philosophy because, as philosophy, it needs to be systematic – indifferent, in other words, to the most particular details of the life world. But the subject of this philosophy is certainly the stuff of novels: dramas of sympathy, judgments of circumstances and the precise analysis of the qualities and intentions suffusing different acts (including the quality of failing to be concrete in one’s observations). If the burden of system building were relaxed, Smith too might write volubly about the “satisfactions” one finds “in the little occurrences of common life.”
The Visualizing English Print group is using new visualization tools to study genre dynamics in our corpus of texts spanning the years 1530-1799. While far from comprehensive, the corpus spans an interesting period in the history of English print. Most literary historians, for example, would agree that this is the period when the novel emerges as a distinct generic form. One of the tools we are using – a re-orderable matrix and topic modeling tool called Serendip – has generated topics that illuminate this development in our corpus. We began that work by first labeling all 1080 items by genre, something we had to do if we were going to see any patterns in the larger collection. (A downloadable spreadheet of both the items and the genre labels applied to them appears in a spreadsheet here.) This post deals with two algorithmically generated topics that we found useful in identifying items we had previously labeled “prose fiction” and “philosophy.” The topics were generated through a process known as Latent Derichlet Allocation (LDA), a technique commonly used to sort through web pages or documents in large collections of texts.
In exploring the VEP corpus with Serendip, we saw that our prose fiction texts – particularly the eighteenth century novels – were related to our philosophy texts in some interesting ways. We began to understand that relationship when we noticed that prose fiction and philosophy texts shared the topics that are present in large measure in each of them individually. (A topic is a collection of words that tend to co-occur with one another in individual documents; one might think of them as “ingredients” that are mixed together to create the full variety of documents in the corpus.) The first of these topics was characteristically present in texts classed as prose fiction, which was reasonably interesting. More interesting still: we found that the type of texts next most likely to contain words from this “prose fiction” topic were those we classed as “philosophy.” And the topic that was most prevalent in philosophy texts – in this case, works of moral philosophy by thinkers such as Smith and Hume – were also present in our prose fiction novels.
Why this overlap or sharing of ingredients? Where does the novel stop and moral philosophy begin? Before attempting an answer, it is important to understand what kinds of works qualified, in our naming game, for membership in these two groups. A complete list of works in the corpus, with their genre classes, can be found at the link above. Below we list only the works in these two classes. Our naming convention begins with a date of publication, short title of the work, author, and assigned genre class. Our dates here refer to the date of the edition transcribed by TCP in a corpus assembled at random: per our earlier post on the corpus, it is composed of 40 randomly selected texts per decade. The corpus was thus specifically not created for the purpose of exhaustive surveying any one literary form. Our purpose, rather, was to see how much we could learn from a relatively small sample of what TCP had transcribed.
1534 ErasmusAgainstWar Erasmus, Desiderius, d. 1536
1532 DespisingTheWorld Erasmus, Desiderius, d. 1536.|Paynell, Thomas
1531 TreatiseSufferFriendsDeath Erasmus, Desiderius, d. 1536
1590 RoyalExchangeAphorisms Rinaldi, Oraziofin /upd.|Greene, Robert, 1558?-1592
1614 LabyrinthOfMansLife Norden, John, 1548-1625?
1576 AnatomyOfTheMind Rogers, Thomas, d. 1616
1580 PatternOfAPassionateMind Rogers, Thomas, d. 1616.|Rogers, Thomas, d. 1616.|H. W
1561 CicerosFiveQuestions Cicero, Marcus Tullius.|Dolman, John
1675 FreedomOfWill Sterry, Peter, 1613-1672
1741 EveryManHisOwnWayEpistle Duck, Stephen, 1705-1756
1752 TheRambler Johnson, Samuel, 1709-1784
1740 TreatiseHumanNatureAbstract Hume, David, 1711-1776
1741 EssaysMoralAndPolitical Hume, David, 1711-1776
1759 EpistlesPhilosphicalAndMoral Kenrick, W. (William), 1725?-1779
1734 EssaysOnSeveralSubjects Forbes of Pitsligo, Alexander Forbes, Lord, 1678-1762
1751 EssaysOnTheCharacteristics Brown, John, 1715-1766
1759 TheoryMoralSentimentsSmith Smith, Adam, 1723-1790
1734 EssayonMan Pope, Alexander, 1688-1744.]
A look at these lists confirms that our corpus contains significant examples of both the eighteenth-century novel (Richardson, Burney, Lennox) and important texts in the history of moral philosophy, for example, Adam Smith’s Theory of Moral Sentiments. Noting these landmarks, we want now to explore this overlap in vocabularies and share some preliminary thoughts about why novels share the vocabulary of moral philosophy and how those vocabularies function in each genre.
The next three posts are structured as a dialogue, beginning with some remarks by Michael Witmore (a Serendip user) and Eric Alexander (Serendip’s designer). These remarks focus on how Serendip helped them to pinpoint this kinship between the two genres. In the next post, we have a “reaction” from a scholar of the Eighteenth Century Novel, Julie Park, who was recently a fellow at the Folger Shakespeare Library where Serendip was tested. Her post, entitled “Telling and Feeling, Aunts and Letters,” introduces some historical context for the development of the eighteenth century novel, moving on to show how the topic words associated with the prose fiction texts contribute to the latter’s project of rendering everyday life and moral sensibility for readers. Park offers specific readings of some of the topic words that Serendip flagged as highly present of our clusters of topic words, offering the perspective of a new user/interpreter on the results produced by a software tool still in development. In a final post entitled “What Does Lennox Do with Moral Philosophy Words?” Witmore expands on Park’s analysis, offering an interpretation of the differences between the two topical fields we are associating with the novel and moral philosophy.
Serendip
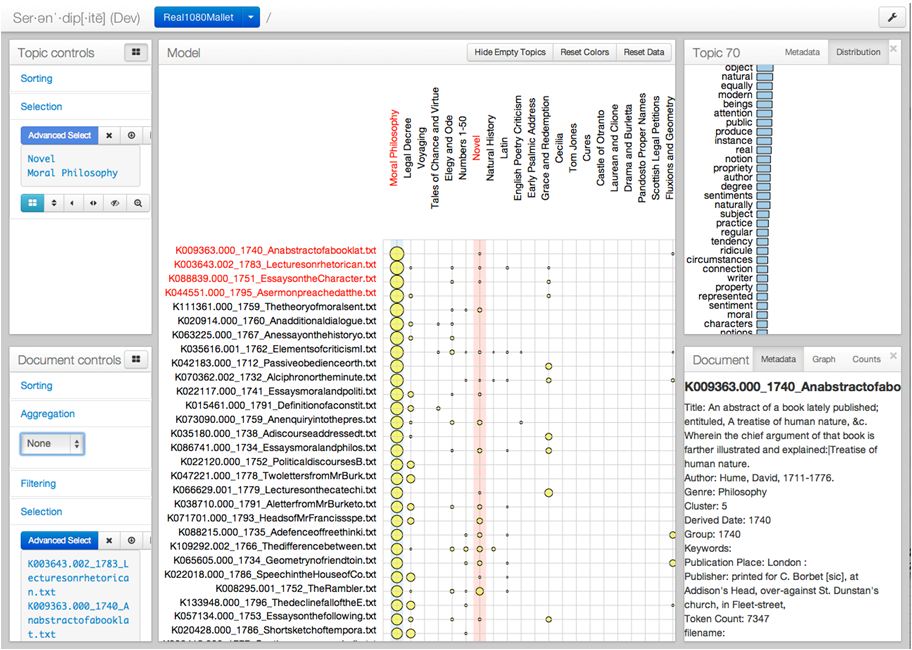
We begin with a few words about what Serendip is and how it works. At its highest level, Serendip allows users to visualize how topics are distributed across a document set. “Topics,” in this instance, are significant collections of words (extracted by an algorithm known as Latent Dirichlet Allocation, or LDA) that tend to occur in the same documents across a corpus. Serendip displays the occurrence of these topics in a re-orderable matrix that plots documents, in the vertical axis, against topics, in the horizontal axis, indicating individual proportions with circular glyphs of varying size. Documents can be displayed individually or in aggregate groups. After some tuning by Alexander, who is the original designer of Serendip, a user (in this case, Witmore) takes the tool and begins to explore these topics, looking at what words they contain and what texts score highest on each topic. The power of the tool is the ability it gives its user to re-order the matrix according to individual topics, texts, or text groups.
We are not going to discuss how topic modeling works in this post. (A good explanation can be found on Ted Underwood’s blog.) We do want to show something that happened when we began exploring this corpus using the topics that had been generated for us. You’ll see several screen shots below. For the time being, focus on the center pane with the yellow circles that look like planets. Across the top are the topics, which were named according to Witmore’s best guess at what they captured in texts. (Naming topics is a task that seems to have been designed for human beings: the judgments are highly contextual and built upon the study of examples.) Witmore’s topic names were based, first, on his examination of the word distribution in that topic (the window at right labeled “Novel”), but also on his knowledge of the works displayed in the lower right hand pane. (The lower right hand pane displays individual texts within a given subgroup of texts – here the ones that our bibliographer had labeled “prose fiction”). A lot of this is subjective, which is as it should be.
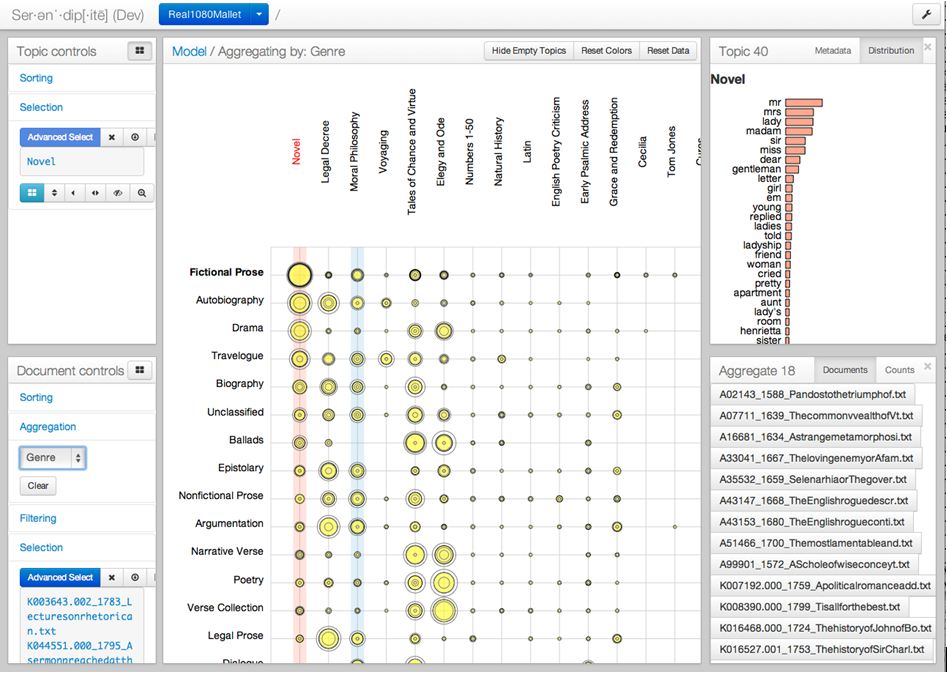
On this screen, Witmore had selected the topic which he had named “Novel” at the top left portion of the page and then re-ordered the matrix to show all of the genre types which contain those topic words. (The genres are listed vertically in descending order down the red column at left.) The size of these circles represents the frequency with which this topic occurs in a given group of texts; additional information about outliers is furnished by the Saturn-like rings. We can also disaggregate this group and see how individual texts score on this topic, again in descending order:
Witmore’s initial name for this topic was “Novel,” which seems to accord well with the actual texts that are highly rated on this topic: Charlotte Lennox’s Henrietta, followed by two parts of a Richardson novel, a few dramas, and then more novels by Lennox and Richardson. Knowing that he needed to consult an expert, he decided to talk to Julie Park, a scholar of eighteenth century literature, whom he hoped could help him understand this topic. The initial identification of this topic, however, seemed right given that the matrix in the previous screenshot identifies texts classed as “Fictional Prose,” “Autobiography,” “Drama,” “Travelogue,” and “Biography” as high scorers on this topic. (“Legal Prose,” not so much, which is all for the good.)
Neither Witmore nor Park was surprised to see that the words making up the “Novel” topic (mr, mrs, lady, madam, sir, miss, dear) occur frequently in epistolary novels, which make up a large proportion of this group. For structural reasons, the narrative voice of epistolary novels must register and mark an awareness of addressee (Mr., Sir, etc.); letters also recount dialogue (and so, once again, use terms of address and quotational words like “cried,” “told,” “replied,”). The drama of these novels is a social one; we are not surprised to find words that tag an individual’s social standing. (Technical terms from geometry or botany are not featured high on this list, for example.) The initial finding suggested to us that we were operating in the same universe as the tool; it was doing things we understood.
But you can always know what you know in new ways and you can also try to describe that knowledge in different terms. This is what we were interested in doing with the tool that Eric had built. Re-ordering was the next step in the process.
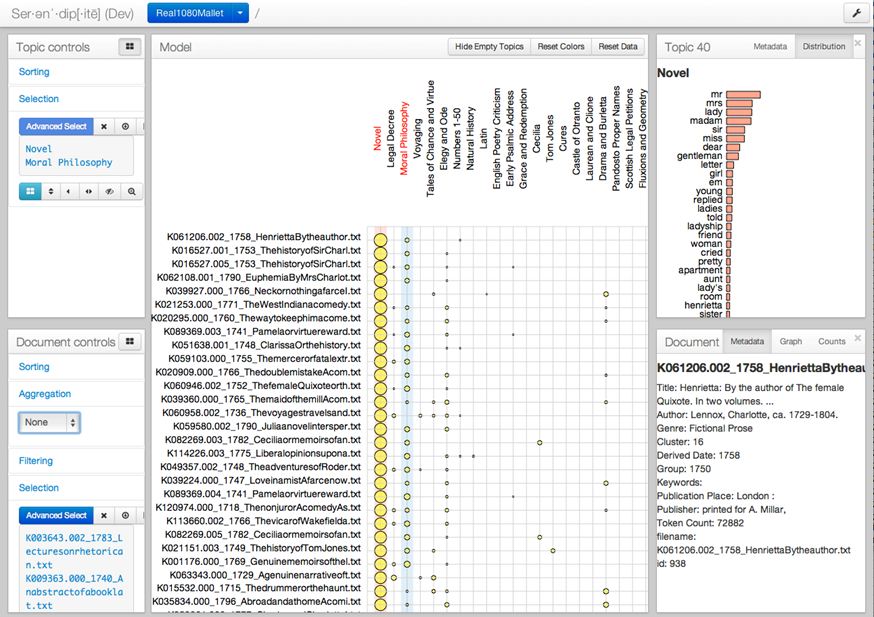
Look now at a second re-ordering of the matrix, this time on the basis of a topic named “Moral Philosophy” which is the third column to the right in light blue. The topic words here are obviously abstract – the highest scorers are words like “object,” “mankind,” “idea,” “system” – but further down the list, they seem to focus on the dynamics of moral deliberation. “Sentiment,” “moral,” “characters,” “propriety” and “sentiments” are all words that seem useful in this context. (One never knows for sure how words are going together or behaving, of course, until one sees these words working in a text.) Here again, the ratings of genre groups in descending order seemed plausible, beginning with “Philosophy” and then moving through “Argumentation” and other forms of “Nonfiction Prose.”
We get an even better sense when we rate items on this topic at a more granular level, going work by work in descending order. The “Moral Philosophy” topic – the blue, leftmost column – is now rating individual works:
An abstract of David Hume’s Treatise of Human Nature is the top scorer here, and a little further down one sees Adam Smith’s Theory of Moral Sentiments. Calling this topic “Moral Philosophy” rather than “Natural Philosophy” or “Metaphysics” was seeming like the right move.
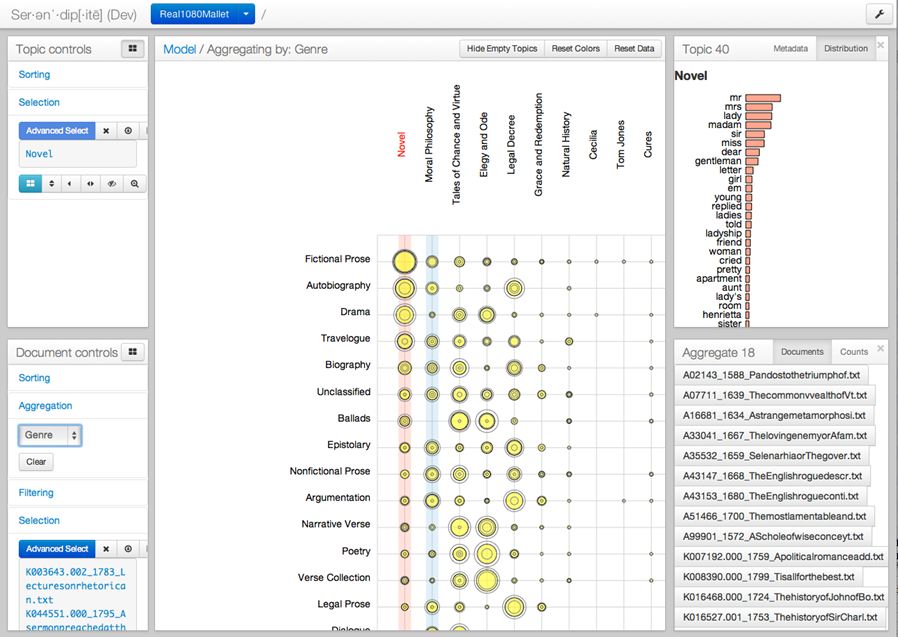
Now look at what happens when we re-organize the matrix according to the human generated genre designations on the left hand side – essentially asking which computer generated topics a human designated genre group is made up of. Returning to a view that shows us the groups down the left hand side, we re-ordered the matrix according to the topic scores of texts that a human being has classified as “Fictional Prose:”
“Fictional Prose” texts are, as a group, rated horizontally on their prevalent topics, again in descending order, now from right to left. What we are seeing now are the topics of which “Fictional Prose” texts are generally composed. The first one listed is “Novel,” to which we say, “so far, so good.” But look just to the right. Going next in sequence, we see that “Moral Philosophy” has moved across the screen to become the second most highly ranked topic for this type of text, followed closely by another topic named “Tales of Chance and Virtue.”
Now things become interesting. Why would prose fictional texts, largely epistolary and high scorers on the “Novel” topic, also be associated with the “Moral Philosophy” topic? What does Charlotte Lennox do that Adam Smith does as well?
To answer this question, we needed to begin looking at the topic words in context, which we did through Serendip’s ability to drill down into the documents, allowing us to view passages. We generated several views of the texts that showed texts by Charlotte Lennox and Adam Smith with topic words highlighted in different colors (red for the novel, blue for moral philosophy). To get a sense of what the “novel” words in red are actually doing in context, we asked Julie Park to produce the reflection that follows in the next post, which begins with an analysis of novel words in Charlotte Lennox’s Euphemia. We also furnished her with several screenshots of Adam Smith’s Theory of Moral Sentiments, since this text contained a significant number of topic words that we are associating with moral philosophy. We post here a few screenshots of each work as a preface to the next installment.
The written version of a paper we gave in Paris last year (2013) has just been published by the Société française Shakespeare. Here is the paper (which is in English), and here are the citation details:
Pour citer cet article
Référence papier
Jonathan Hope et Michael Witmore, « Quantification and the language of later Shakespeare », Actes des congrès de la Société française Shakespeare, 31 | 2014, 123-149.
Référence électronique
Jonathan Hope et Michael Witmore, « Quantification and the language of later Shakespeare », Actes des congrès de la Société française Shakespeare [En ligne], 31 | 2014, mis en ligne le 29 avril 2014, consulté le 07 mai 2014. URL : http://shakespeare.revues.org/2830
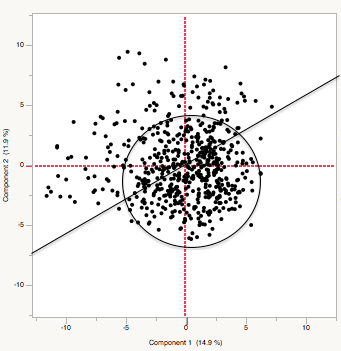
591 Early Modern Dramas plotted in PCA space, with ‘core’ group circled and variation boundary marked (line)
American/Australian tour
In March-April 2014, I’ll be in the USA giving a series of talks and conference presentations based around Visualising English Print, and our other work. In June I’ll be in Newcastle, Australia for the very exciting Beyond Authorship symposium.
I’ll address a series of different themes in the talks, but I’ll use this page as a single resource for references, since they are all (in my head at least) related.
Some of the talks will be theoretical/state of the field; some will be specific demonstrations of tools. The common thread is something like, ‘what do we think we are doing?’.
Here’s a general introduction (there’s a list of venues afterwards).
1 Counting things
Quantification is certainly not new in literary criticism, but it is becoming more noticeable, and, perhaps, more central as critics analyse increasingly large corpora. The statistical tools we use to explore complex data sets (such as Shakespeare’s plays or 20,000 texts from EEBO-TCP) may appear like magical black boxes: feed in the numbers, print out the diagrams, wow your audience. But what is happening to our texts in those black boxes? Scary mathematical things we can’t hope to understand or critique?
I want to consider the nature of the transformations we perform on texts when we subject them to statistical analysis. To some extent this is analogous to ‘traditional’ literary criticism: we have a text, and we identify other texts that are similar or different to it:
How does Hamlet relate to other Early Modern tragedies?
This is a question equally suited to quantitative digital analysis, and traditional literary critical approaches. The ways we define and approach our terms will differ between the two modes, as will the evidence employed, but essentially both answers to this question would involve comparison and assessment of degrees of similarity and difference.
But there is also something very different to traditional literary criticism going on when we count things in texts and analyse the resulting spreadsheets – something literary scholars may feel unable to understand or critique. What exactly are we doing when we ‘project’ texts into hyper-dimensional spaces and use statistical tools to reduce those spaces down to something we can ‘read’ as humans?
Perhaps surprisingly, studying library architecture, book history, information science, and cataloguing systems may help us to think about this. Libraries organised by subject ‘project’ their books into three-dimensional space, so that books with similar content are found next to each other. Many statistical procedures function similarly, projecting books into hyper-dimensional spaces, and then using distance metrics to identify proximity and distance within the complex mathematical spaces our analysis creates.
Once we understand the geometry of statistical comparison, we can grasp the potential literary significance of the associations identified by counting – and we can begin to understand the difference between statistical significance and literary significance, and see that it is the job of the literary scholar, not the statistician, to decide on the latter. A result can be statistically significant, but of no interest in literary terms – and findings that do not qualify for statistical significance may be crucial for a literary argument.
2 Evidence
Ted Underwood has been posing lots of challenging, and productive, questions for literary scholars doing, or thinking about, digital work. Perhaps most significant is his recent suggestion that the digital causes problems for literary scholars, who are used to basing their arguments, and narratives, on ‘turning points’ and exceptions. Digital evidence, however, collected at scale, tells stories about continuity and gradual change. A possible implication of this is that the shift to digital analysis and evidence will fundamentally change the nature of literary studies, as we break away from a model that has arguably been with us only since the Romantics, and return (?) to one which traces long continuities in genre and form.
One way of posing this question: does the availability of large digital corpora and tools put us at the dawn of a new world, or are we just in for more (a lot more) of the same?
4 References and resources (these are grouped by topic)
(a) Statistics and hyper-dimensionality
Mick Alt, 1990, Exploring Hyperspace: A Non-Mathematical Explanation of Multivariate Analysis (London: McGraw-Hill) – the best book on hyper-dimensionality in statistical analysis: short, clear, and conceptually focussed
Most standard statistics textbooks give accounts of Principal Component Analysis (and Factor Analysis, to which it is closely related). We have found Andy Field, Discovering Statistics Using IBM SPSS Statistics: And Sex and Drugs and Rock and Roll (London: 2013, 4th ed.) useful.
Curiously, Early Modern drama, in the shape of Shakespeare, has a significant history in attempts to imagine hyper-dimensional worlds. E.A. Abbott, the author of A Shakespearian Grammar (London, 1870), also wrote Flatland: A Romance of Many Dimensions (London, 1884), an early science fiction work full of Shakespeare references and set in a two-dimensional universe.
The significance of Flatland to many who work in higher-dimensional geometry is shown by a recent scholarly edition sponsored by the Mathematical Association of America (Cambridge, 2010 – editors William F. Lindgren and Thomas F. Banchoff), and its use in physicist Lisa Randall’s account of theories of multiple dimensionality, Warped Passageways (New York, 2005), pages 11-28 (musical interlude: Dopplereffekt performing Calabi-Yau Space – which refers to a theory of hyper-dimensionality).
Flatland itself is the subject of a conceptual, dimensional transformation at the hands of poet/artist Derek Beaulieu:
Richard Gameson, 2006, ‘The medieval library (to c. 1450)’, Clare Sargent, 2006, ‘The early modern library (to c. 1640), and David McKitterick, 2006, ‘Libraries and the organisation of knowledge’, in Elizabeth Leedham-Green and Teressa Webber (eds), The Cambridge History of Libraries in Britain and Ireland vol. 1, ‘To 1640’, pp. 13-50, 51-65, and 592-615
Jane Rickard, 2013, ‘Imagining the early modern library: Ben Jonson and his contemporaries’ (unpublished paper presented at Strathclyde University Languages and Literatures Seminar)
On data, information management and catalogues:
Ann M. Blair, 2010, Too Much To Know: Managing Scholarly Information before the Modern Age (New Haven: Yale)
Markus Krajewski, 2011, Paper Machines: About Cards & Catalogs 1548-1929 (Cambridge, MSS: MIT) – on Conrad Gessner
Daniel Rosenberg, 2013, ‘Data before the Fact’, in Lisa Gitelman (ed), Raw Data is an Oxymoron (Cambridge, MSS: MIT), pp. 15-40 – combines digital analysis with a historicisation of the field, and the notion of ‘data’
(c) Ted Underwood and the digital future
Ted Underwood, 2013, Why Literary Periods Mattered: Historical Contrast and the Prestige of English Studies (Stanford) – especially chapter 6, ‘Digital Humanities and the Future of Literary History’, pp. 157-75 – on the strange commitment to discontinuity in literary studies, and the tendency of digital/at scale work to dissolve this into a picture of gradualism – Underwood cites his own work as an e.g. of the resistance scholars using quantification find within themselves to gradualism – and notes the temptation to seek fracture/outlier/turning point narrative
(also see Underwood’s discussion with Andrew Piper on Piper’s blog: http://bookwasthere.org/?p=1571 – balancing numbers and literary analysis – and Andrew Piper, 2012, Book There Was: Reading in Electronic Times (Chicago) – see chapter 7, ‘By The Numbers’ on computation, DH).
‘longue durée’ History – Underwood has suggested that historians are more comfortable than literary scholars with the ‘long view’ that tends to come with digital evidence, and David Armitage and Jo Guldi have been arguing that the digital is shifting history back to this mode:
David Armitage, 2012, ‘What’s the big idea? Intellectual history and the longue durée’, History of European Ideas, 38.4, pp. 493-507
(d) Overview/examples of Digital work:
Early Modern Digital Agendas was an NEH-funded Institute held at the Folger Shakespeare Library in 2013. The EMDA website has an extensive list of resources for Digital work focussed on the Early Modern period.
Text
An excellent account of starting text-analytic work by a newcomer to the field:
An example of an info-heavy, ‘reference’ site that makes excellent use of maps – The Museum of the Scottish Shale Oil Industry (!): http://www.scottishshale.co.uk
Bpi1700 makes a database of ‘thousands’ of prints and book illustrations available ‘in fully-searchable form’. However, searching is text-based (see http://www.bpi1700.org.uk/jsp/)
Development halted? ‘Although the main development work has been completed, improvements will continue to be made from time to time. If you have problems or suggestions please contact the project (see the ‘contact’ page).’ http://www.bpi1700.org.uk/index.html
The Ukiyo-e Search site is an amazing resource that represents something genuinely new (rather than just an extension of previously existing word-based catalogue searching), in that it allows searching via an uploaded image. For example, a researcher can upload a phone-image of a print she discovers in a library, and see if the same/similar prints have been previously described, and how many other libraries have copies or versions of the print. The search is ‘fuzzy’ and will often detect different states of altered woodblocks. [Thanks to @GilesBergel for the news that a similar functionality is coming to the Bodleian Ballads project.]
The Ukiyo-e site was created by one person, John Resig, an enthusiast for Ukiyo-e, who saw the need for the site as a research tool. Development and expansion on-going.
‘The database currently contains over 213,000 prints from 24 institutions and, as of September 2013, has received 3.4 million page views from 150,000 people.’ http://ukiyo-e.org/about
And finally, pictures of my kittens Arthur and Gracie, who will feature in the talks:
Arthur can work a computer (he wrote the title of this post).