Here begins a series of posts on a larger dataset we have been studying at Wisconsin under the auspices of “Visualizing English Print, 1530-1800,” a Mellon funded research project that brings together computer scientists and literary scholars from several institutions — UW, Madison, Strathclyde University (U.K.), and the Folger Shakespeare Library. A profile of the project members appears here.
I would like to begin by posting the data set that we are working with, which consists of texts drawn from the EEBO-TCP corpus. We assembled the corpus by drawing 40 texts at random from 27 decades within the corpus, beginning with the decade 1530-1539 and ending with 1790-1799. Texts under 500 words in length were excluded from selection. We knew that this selection could not be truly random, since the TCP project selected texts for transcription that it felt would be of interest to scholars. (Full disclosure: I am on the TCP Executive Board.) But we did want to frustrate the natural urge to pick texts we knew and liked: that would limit the kind of lexical and generic variation we want to study.
These texts are now being tagged and analyzed according to several different schemes. Members of our team have created tools for visualizing patterns of variation within the corpus, tools that we want eventually to share with others. There are two techniques I want to discuss: analysis of texts using a tagging scheme derived from the original Docuscope (what we call “Docuscope Junior”) and analysis of texts using a topic model. The former was implemented by Mike Gleicher, the latter by Eric Alexander.
A .csv.zip file showing the texts and their scores on both the DSJ variables and then the topics (each in ascending alphabetical order) can be downloaded at the following location: 1080forWDS. A zipped copy of a folder containing HTML pages of all the documents in the dataset, tagged with DSJ, can be downloaded here. (Note that some of these files, for example Ralegh’s History of the World, are very large and may swamp your browser.) These pages were generated by a utility called Ubiqu+ity, a Wisconsin-designed tagging tool that implements the DSJ tagging scheme. Ubiqu+ity can also tag a corpus with a user-defined tagging scheme, which should enable us to try different schemes on the same corpus.
Now a first picture of the corpus, showing a Docuscope LAT (Language Action Type) that increases steadily over time in the corpus:
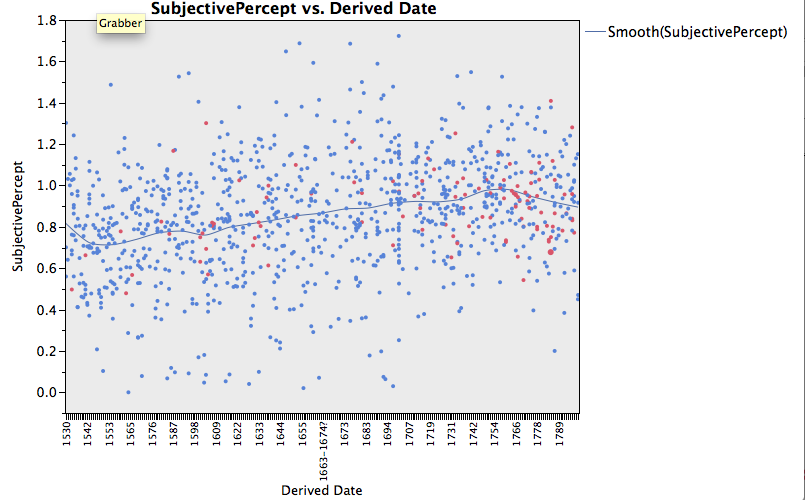
Perhaps this is not a surprising trend, but we were pleased to see something right away that made sense. Red dots in this graph are dramatic texts, whereas the blue texts are all others. Here is an example of a text encoded by DSJ that is high on this variable. You can scroll down on your HTML browser at left, click on SubjectivePercept, and all of the items so tagged will be highlighted. The text is Abroad and at home: A comic opera, in three acts. Now performing at the Theatre-Royal, Covent-Garden. By J. G. Holman, title page publication date 1796, which is the red dot significantly elevated above the trend line, at the far right. You can view it here:
K035834.000_1796_AbroadandathomeAcomi_Docuscope
Please note that the texts passed through DSJ were modernized using VARD 2, developed at Lancaster. The topic model was implemented on texts that were not modernized, although data from both trials are included in the .csv file above.