We’re currently working with two versions of our drama corpus: the earlier version contains 704 texts, while the later one has 554, the main distinction being that the later corpus has a four-way genre split – tragedy, comedy, tragicomedy, and history – while the earlier corpus also includes non-dramatic texts like dialogues, entertainments, interludes, and masques. Recently we’ve been doing PCA experiments with the 704 corpus to see what general patterns emerge, and to see how the non-dramatic genres pattern in the data. The following are a few of the PCA visualisations generated from this corpus, which provide a general overview of the data. We produced the diagrams here using JMP. The spreadsheets of the 704 and 554 corpora are included below as excel files – please note we are still working on the metadata.
Overview (click to enlarge images):
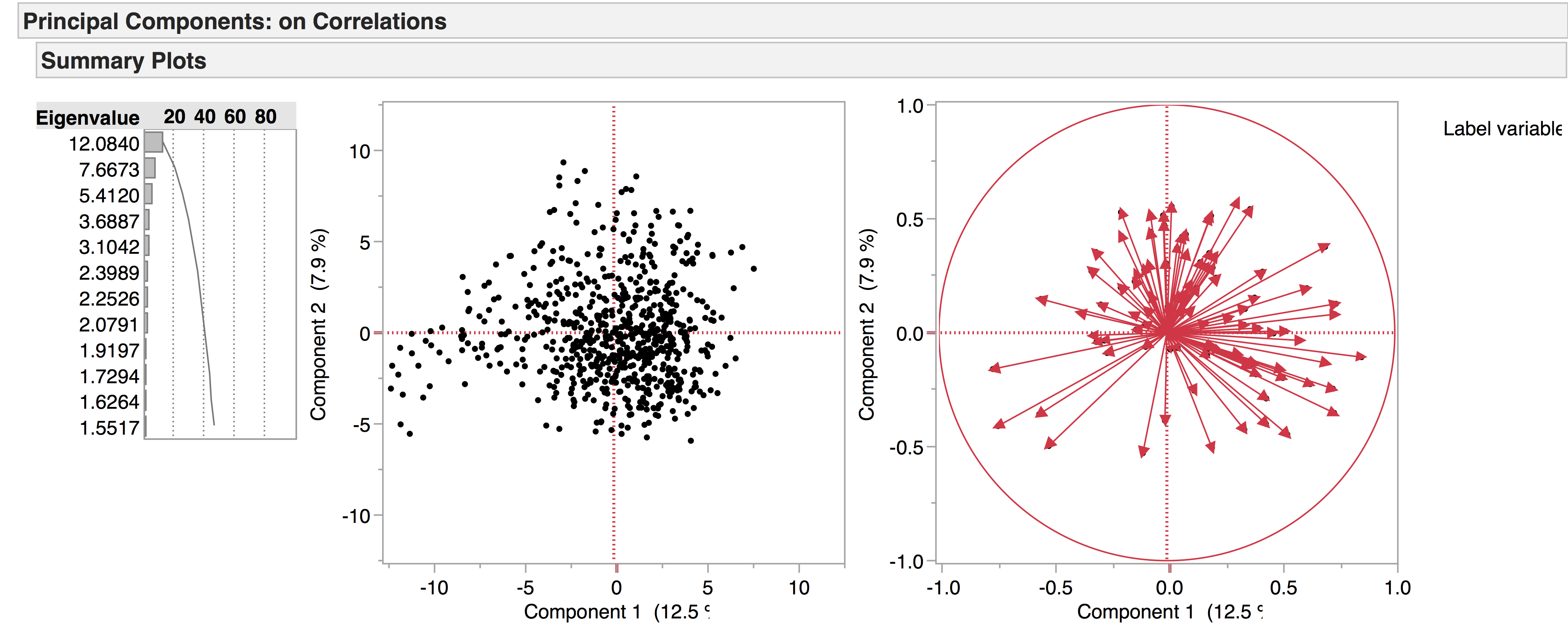
This is the complete data set visualised in PCA space. All 704 plays are included, but LATs with frequent zero values have been excluded.
Genre:
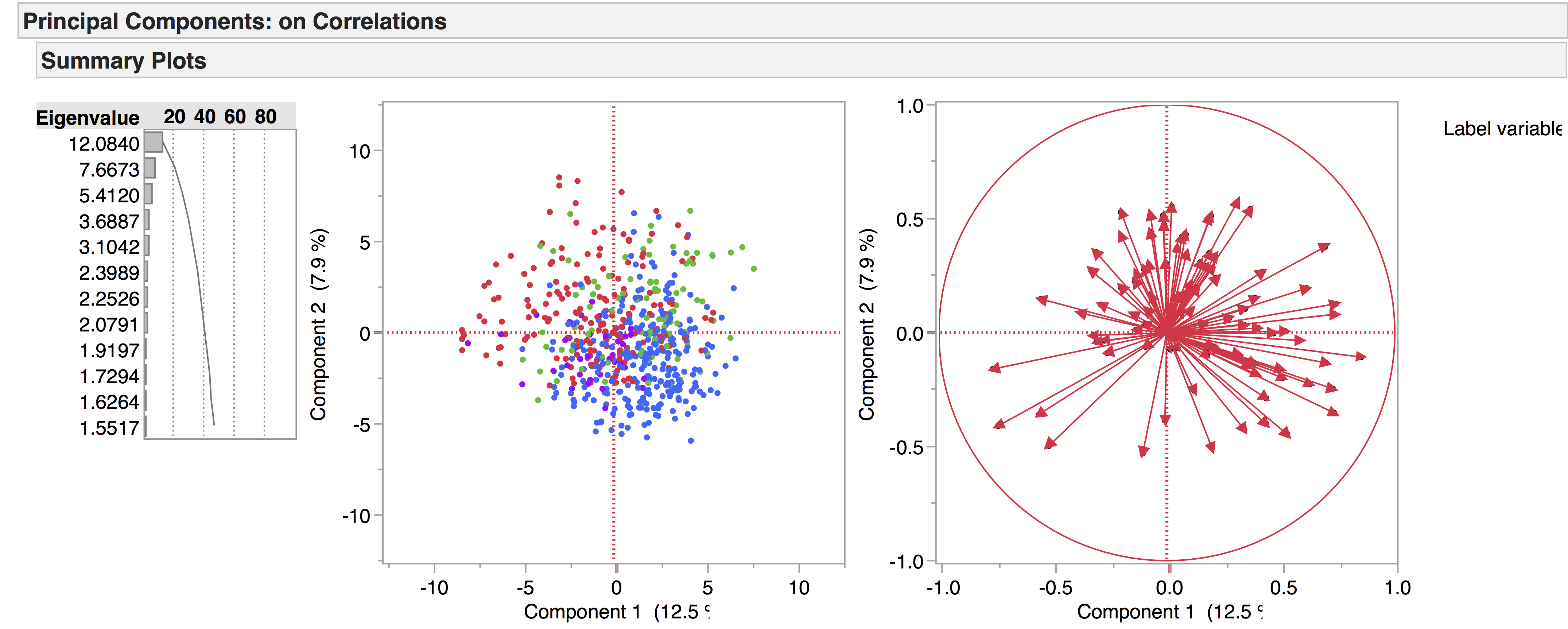
If we highlight the genres, it looks like this:
Comedies = red
Dialogues = green
Entertainments = blue
Histories = orange
Interludes = blue-green
Masques = dark purple
Non-dramatics = mustard
Tragicomedies = dark turquoise
Tragedies = pink-purple
If we tease this out even more – hiding, but not excluding, the non-dramatic genres – there is a clear diagonal divide between tragedies (red) and comedies (blue):
[Michael Witmore, Jonathan Hope, and Michael Gleicher, forthcoming, ‘Digital Approaches to the Language of Shakespearean Tragedy’, in Michael Neill and David Schalkwyk, eds, The Oxford Handbook of ShakespeareanTragedy (Oxford)]
With tragicomedies (green) and histories (purple) falling in the middle:
It seems that tragedies and comedies are characterised by sets of opposing LATs. The LATs associated with comedy are those capturing highly oral language behaviour, while those associated with tragedy capture negative language and psychological states. Tragicomedies and histories – although we have yet to investigate them in detail – seem to occupy an intermediate space. If we unhide the non-dramatic genres, we can see how they pattern in comparison.
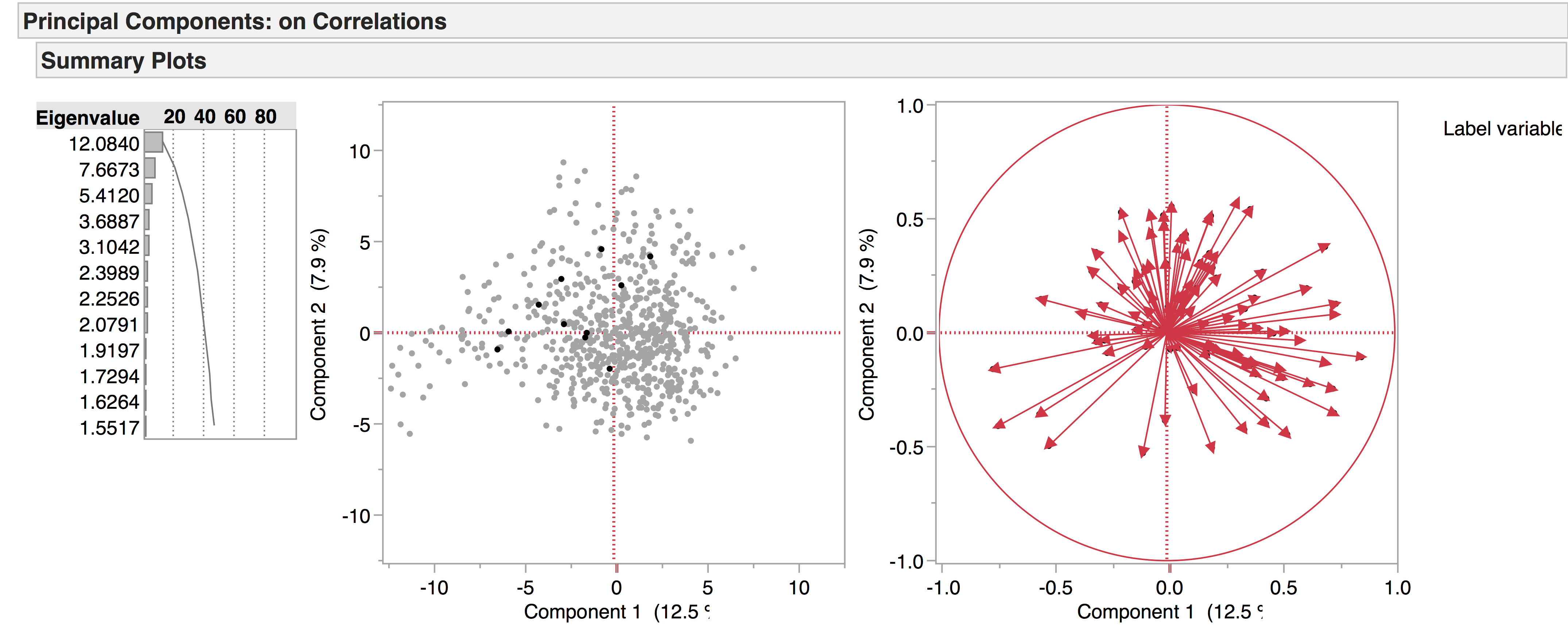
In spite of their name, dialogues are not comprised of rapid exchanges (e.g. Oral Cues, Direct Address, First Person etc., the LATs which make up the comedic side of the PCA space) but instead have lengthy monologues, which might explain why they fall mostly on the side of the tragedies:
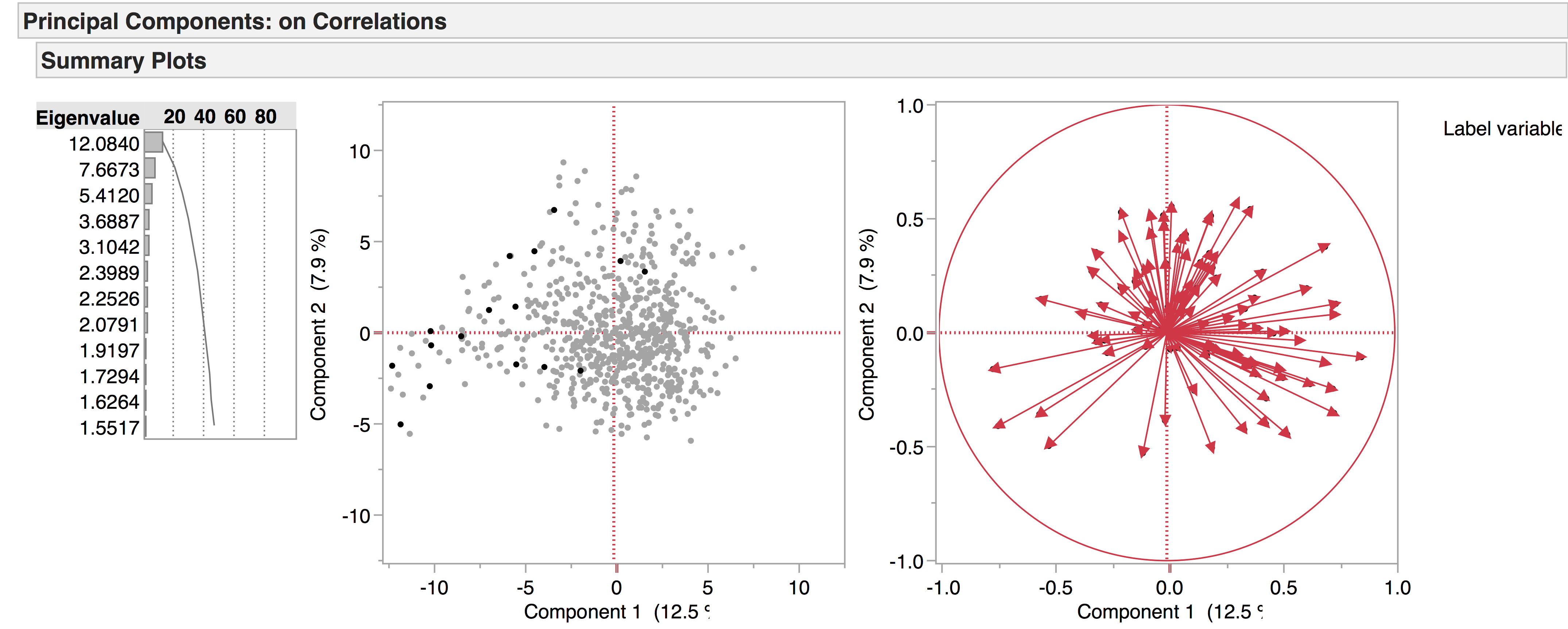
Entertainments do not seem to be linguistically similar to each other:
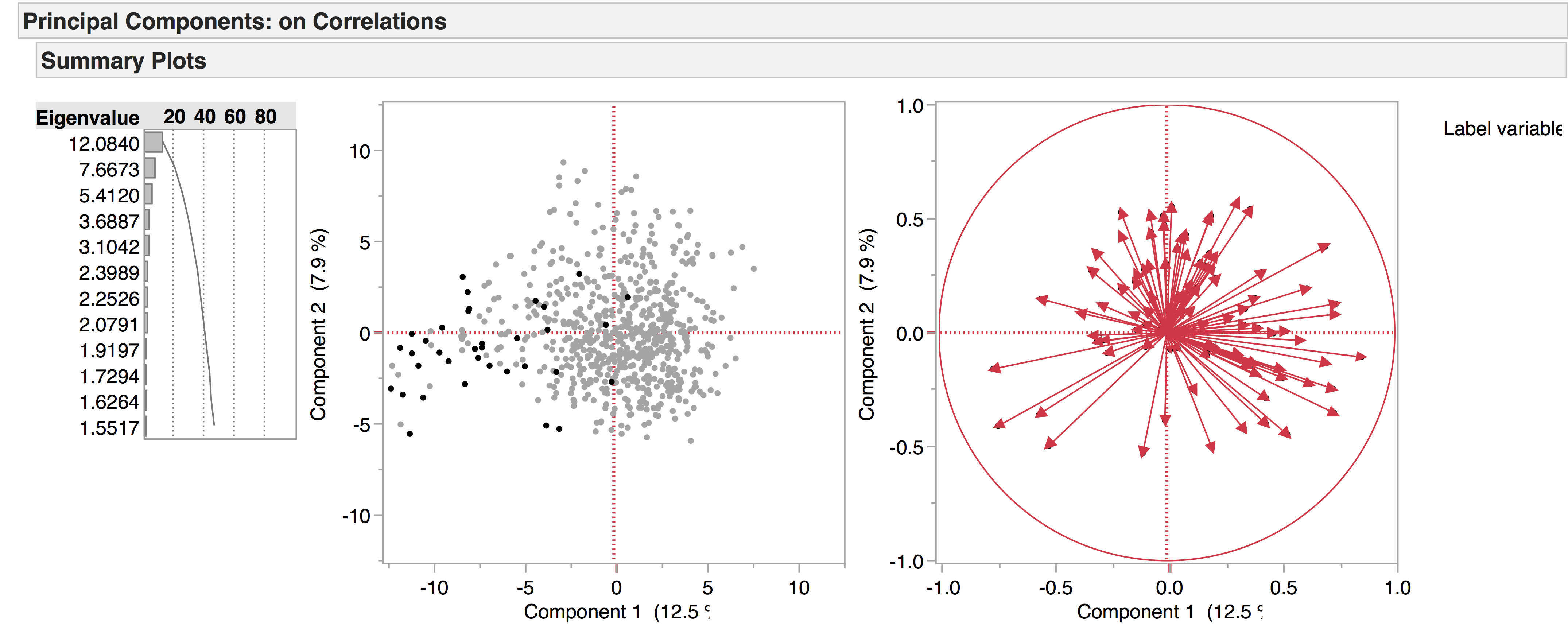
Interludes, on the other hand, seem to occupy a more tightly defined linguistic space:

Masques are pulled towards the left of the PCA space:
Authorship:
Docuscope was designed to identify genre, rather than authorship, so perhaps we should not be surprised that authorship comes through less clearly than genre in these initial trials. We should also bear in mind that there are only 9 genres in the corpus, compared to approximately 200 authors.
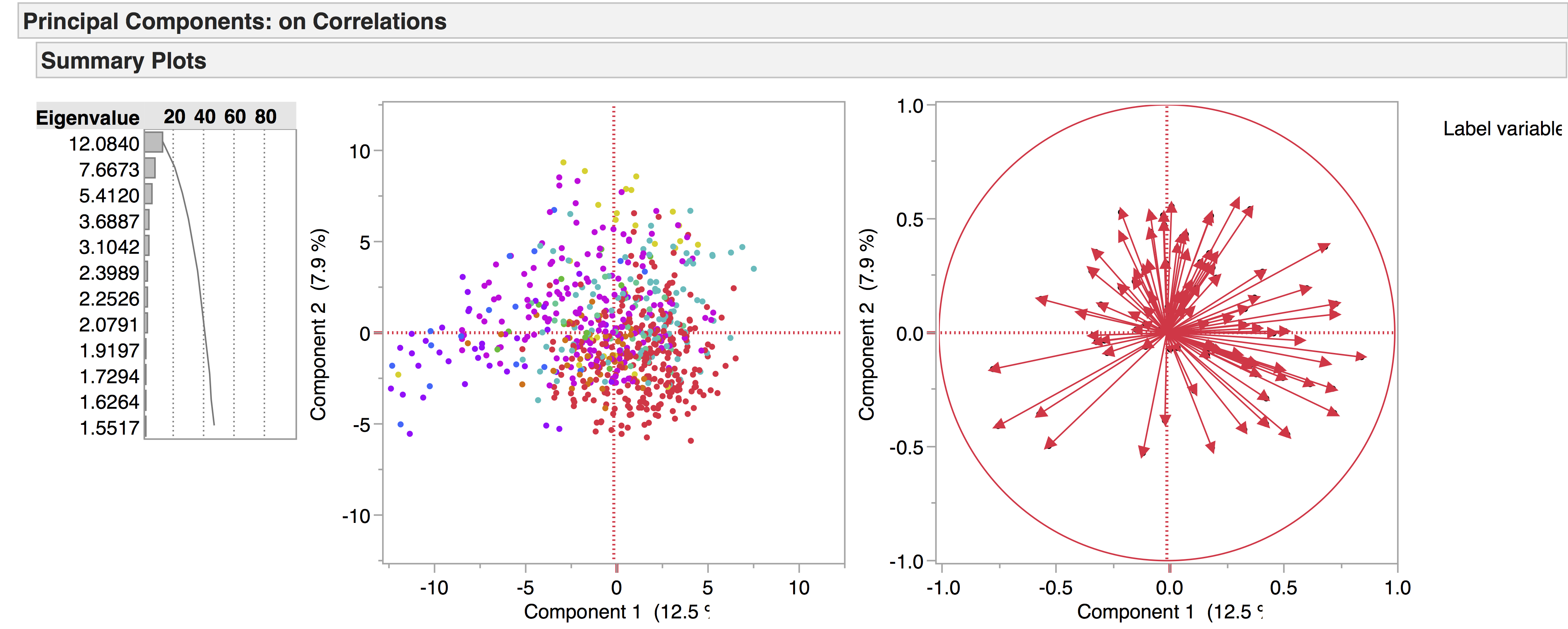
This, for example, shows only the tragedies – all other genres are hidden – and each author is represented by a different colour:
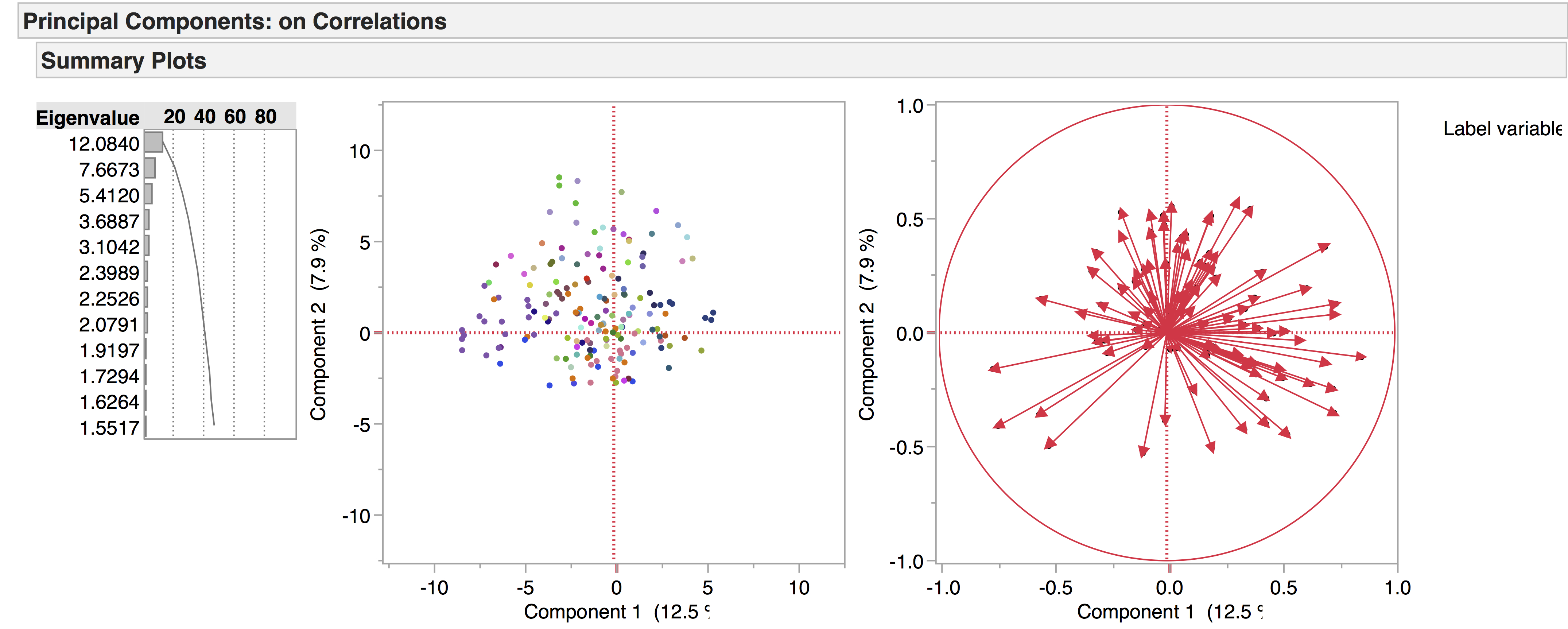
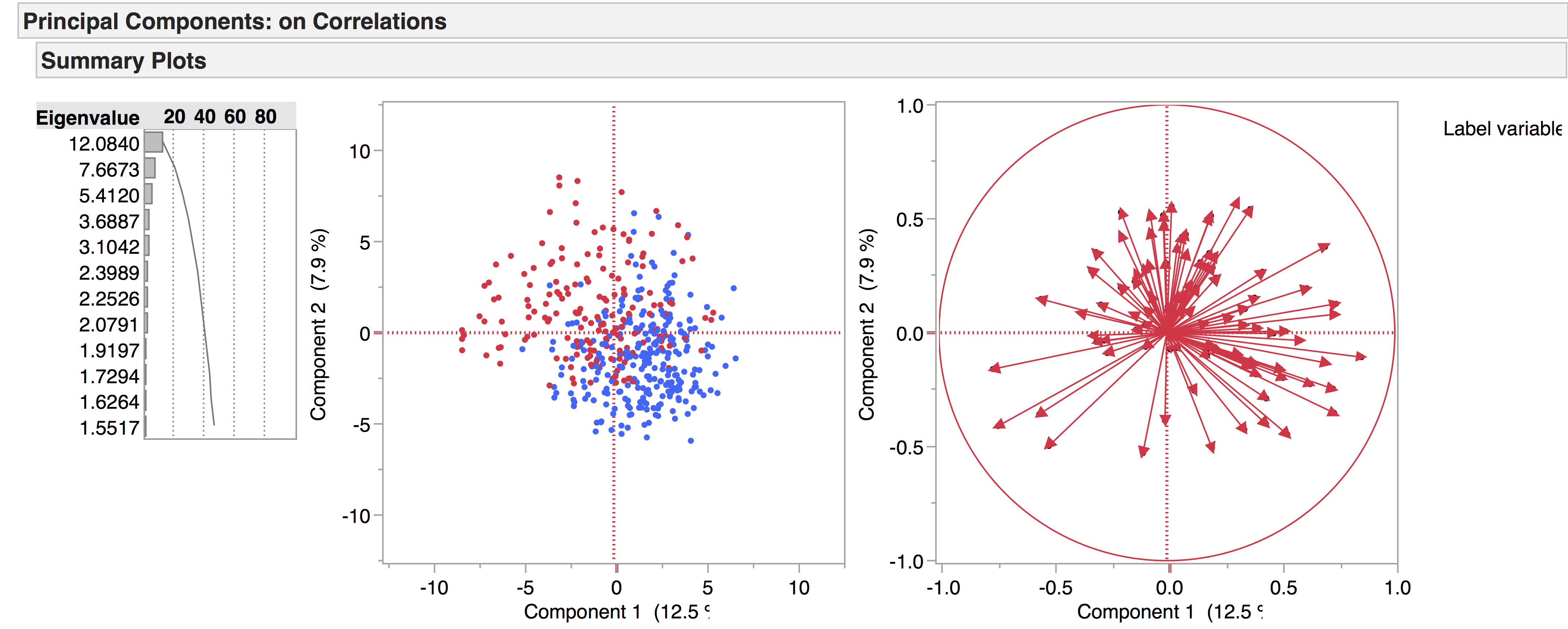
We get a clearer picture when considering a smaller group in relation to the whole – for example, one author compared to all the others. Take Seneca, for example – demonstrated by the purple squares:
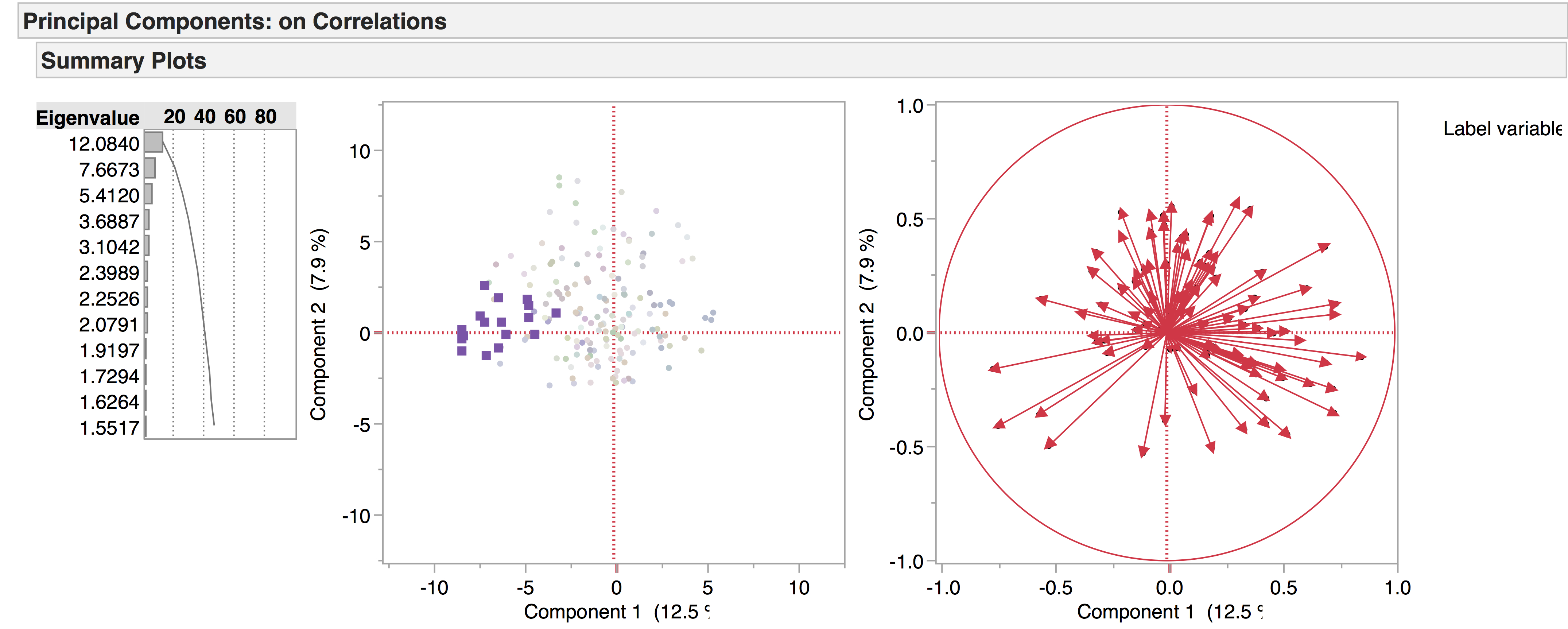
From this we can deduce that Seneca’s tragedies are linguistically similar, as they are grouped tightly together.
Date:
The same applies for looking at date of writing across the corpus, with approximately 100 dates to consider.
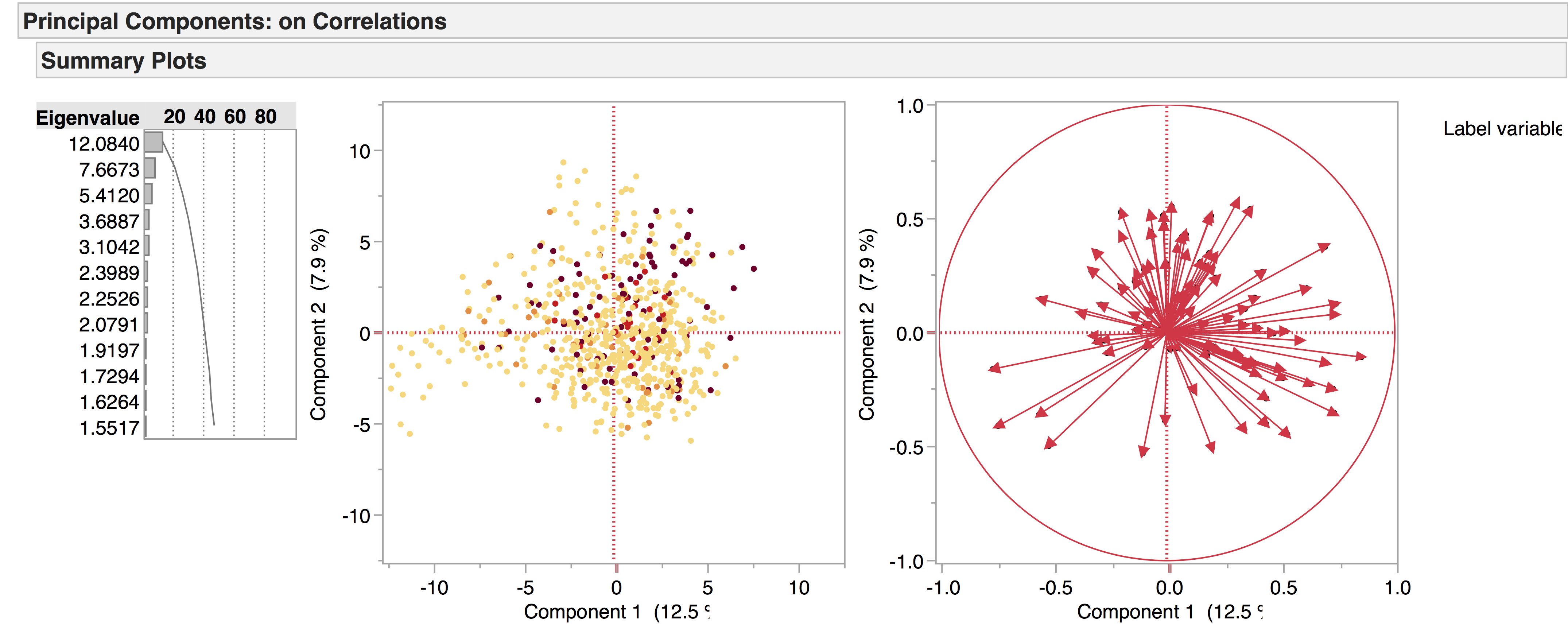
This can be visualised on a continuous scale, e.g. the lighter the dot, the earlier the play; the darker the dot, the later the play. While this has a nice ‘heat map’ effect, it is difficult to interpret:
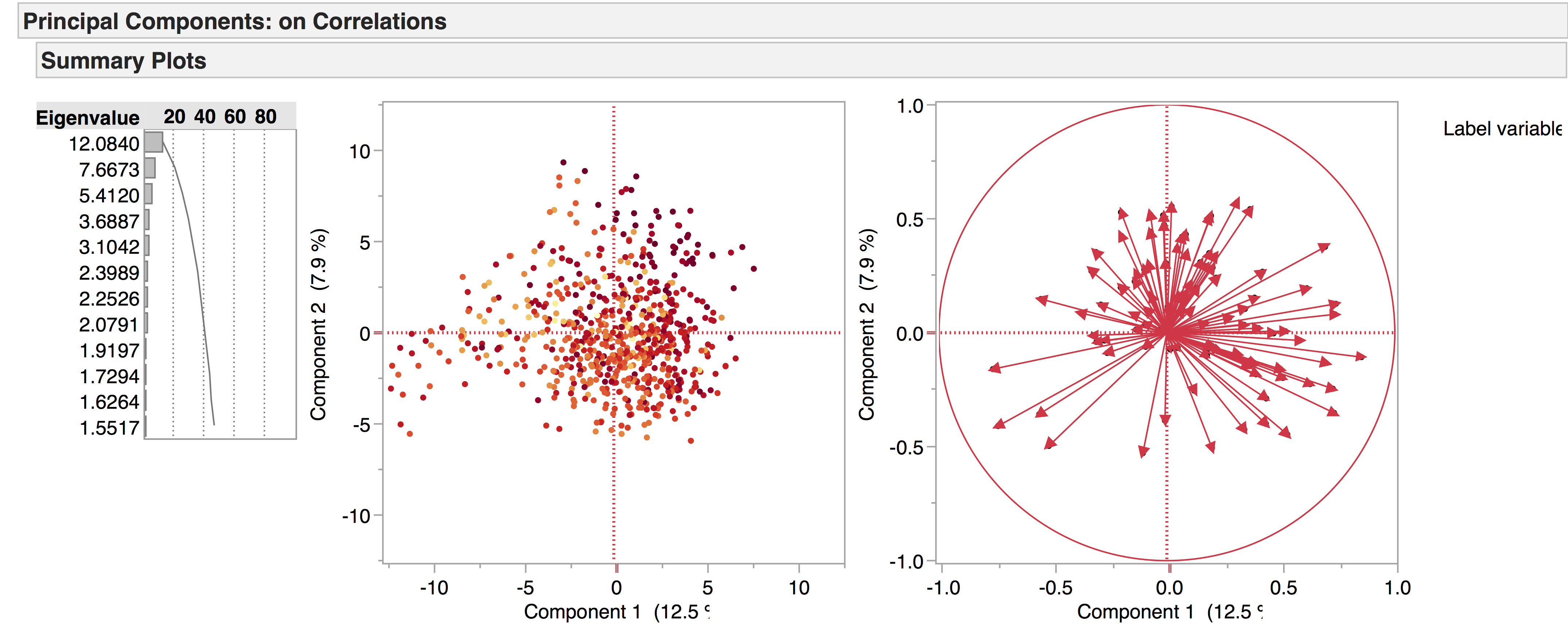
If we narrow this down to three groups of dates – early (red), central (yellow), and late (maroon) – it becomes a little easier to read. As with the Seneca example, the fewer factors there are to consider, the clearer the visualisations become: