(Post by Jonathan Hope and Beth Ralston; data preparation by Beth Ralston.)
It is all about the metadata. That and text processing. Currently (July 2015) Visualising English Print (Strathclyde branch) is focussed on producing a hand-curated list of all ‘drama’ texts up to 1700, along with checked, clean metadata. Meanwhile VEP (Wisconsin branch) works on text processing (accessing TCP texts in a suitable format, cleaning up rogue characters, splitting up collected volumes into individual plays, stripping-out speech prefixes and non-spoken text, modernising/regularising).
We are not the only people doing this kind of work on Early Modern drama: Meaghan Brown at The Folger Shakespeare Library is working on a non-Shakespearean corpus, and Martin Mueller has just released the ‘Shakespeare His Contemporaries’ corpus. We’ve been talking to both, and we are very grateful for their help, advice, and generosity with data. In a similar spirit, we are making our on-going metadata collections available – we hope they’ll be of use to people, and that you will let us know of any errors and omissions.
You are welcome to make use of this metadata in any way you like, though please acknowledge the support of Mellon to VEP if you do, and especially the painstaking work of Beth Ralston, who has compared and cross-checked the various sources of information about Early Modern plays.
We hope to be in a position to release tagged texts once we have finalised the make-up of the corpus, and established our processing pipeline. Watch this space.
Many of the issues surrounding the development of usable corpora from EEBO-TCP will be discussed at SAA in 2016 in a special plenary round-table:

In preparing these lists of plays and metadata we have made extensive use of Martin Wiggins and Catherine Richardson, British Drama 1533-1642: A Catalogue (Oxford), Alfred Harbage, Annals of English Drama 975-1700, the ESTC, and, most of all, Zach Lesser and Alan Farmer’s DEEP (Database of Early English Playbooks).
Definitions and History
One of the usefully bracing things about digital work is that it forces you to define your terms precisely – computers are unforgiving of vagueness, so a request for a corpus of ‘all’ Early Modern drama turns out to be no small thing. Of course everyone defines ‘all’, ‘Early Modern’ and ‘drama’ in slightly different ways – and those using these datasets should be aware of our definitions, and of the probability that they will want to make their own.
The current cut-off date for these files is the same as DEEP – 1660 (though one or two post-1660 plays have sneaked in). Before long, we will extend them to 1700.
By ‘drama’ we mean plays, masques, and interludes. Some dialogues and entertainments are included in the full data set, but we have not searched deliberately for them. We have included everything printed as a ‘play’, including closet dramas not intended for performance.
The immediate history of the selection is that we began with a ‘drama’ corpus chosen automatically by Martin Mueller (using XML tags in the TCP texts to identify dramatic genres). Beth Ralston then checked this corpus against the reference sources listed above for omissions, adding a considerable number of texts. This should not be regarded as ‘the’ corpus of Early Modern drama: it is one of many possible versions, and will continue to change as more texts are added to TCP (there are some transcriptions still in the TCP pipeline, and scholars are working on proposals to continue transcription of EEBO texts after TCP funding ends).
It is likely that each new scholar will want to re-curate a drama corpus to fit their research question – VEP is working on tools to allow this to be done easily.
Files and corpora
1 The 554 corpus
This spreadsheet lists only what we regard as the ‘central’ dramatic texts: plays.
Entertainments, masques, interludes, and dialogues are not included. We have also excluded around 35 play transcriptions in TCP which duplicate transcriptions of the same play made from different volumes (usually a collected edition and a stand-alone quarto).
The spreadsheet includes frequency counts for Docuscope LATs, tagged by Ubiquity, which can be visualised using any statistical analysis program (columns W-EE). For a descriptive list of the LATs, see <Docuscope LATs: descriptions>. For a description of all columns in the spreadsheet, see the <READ ME> file.
[In some of their early work, Hope and Witmore used a corpus of 591 plays which included these duplicates.]
2 The 704 corpus
The 704 corpus spreadsheet lists information for the 554 plays included above, and adds other types of dramatic text, such as masques, entertainments, dialogues, and interludes (mainly drawn from DEEP, and with the same date cut-off: 1660). This corpus also includes the 35 duplicate transcriptions excluded from the 554 spreadsheet.
Docuscope frequency counts are only available for items also in the 554 spreadsheet.
3 The master metadata spreadsheet
Our ‘master metadata’ spreadsheet is intended to be as inclusive as possible. The current version has 911 entries, and we have sought to include a listing for every extant, printed ‘dramatic’ work we know about up to 1660 (from DEEP, Harbage, ESTC, and Wiggins). The spreadsheet does not include every edition of every text, but it does include the duplicate texts found in the 704 corpus. (When we extend the cut-off date to 1700, we expect the number of entries in this spreadsheet to exceed 1500.)
This master list includes all the texts in the 704 list (and therefore the 554 list as well). But it also includes:
• plays which are in TCP but which do not appear in the 554 or 704 corpora (i.e. they were missed first time round). These texts have ‘yes’ in the ‘missing from both’ column (M) of the master spreadsheet.
• plays which are absent from TCP at this time (we note possible reasons for this: some are in Latin, some are fragments, and we assume some have yet to be transcribed). These are texts which have ‘yes’ listed in the ‘missing from both’ column (M) of the master spreadsheet, as well as ‘not in tcp’ listed in the ‘tcp’ column (A).
TCP transcriptions
TCP is one of the most important Humanities projects ever undertaken, and scholars should be grateful for the effort and planning that has gone into it, as well as the free release of its data. It is not perfect however: as well as the issue of texts being absent from TCP, we are also currently dealing with problematic transcriptions on a play-by-play basis. Take Jonson’s 1616 folio (TCP: A04632, ESTC: S112455) for example – it has a very fragmentary transcription, especially during the masques.
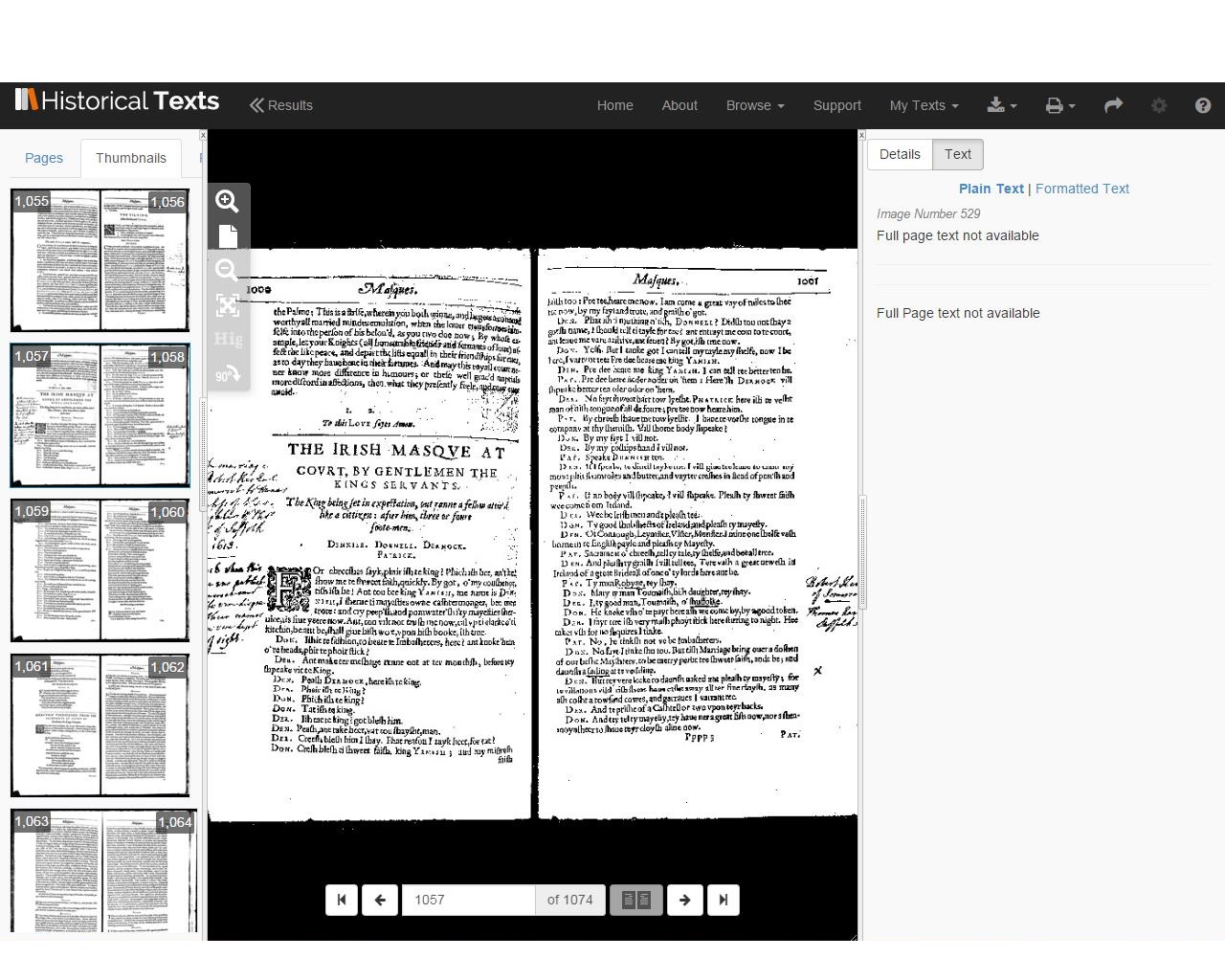
In the above image from The Irish Masque, you can see on the right-hand side that the text for this page is not available.
…However, on the next page the text is there (as far as we can work out, this seems to be due to problems with the original imaging of the book, rather than the transcribers).
Texts with fragmentary transcriptions have been excluded for now, assuming that at some point in the future TCP will re-transcribe them.
As we come across other examples of this, we will add them to page