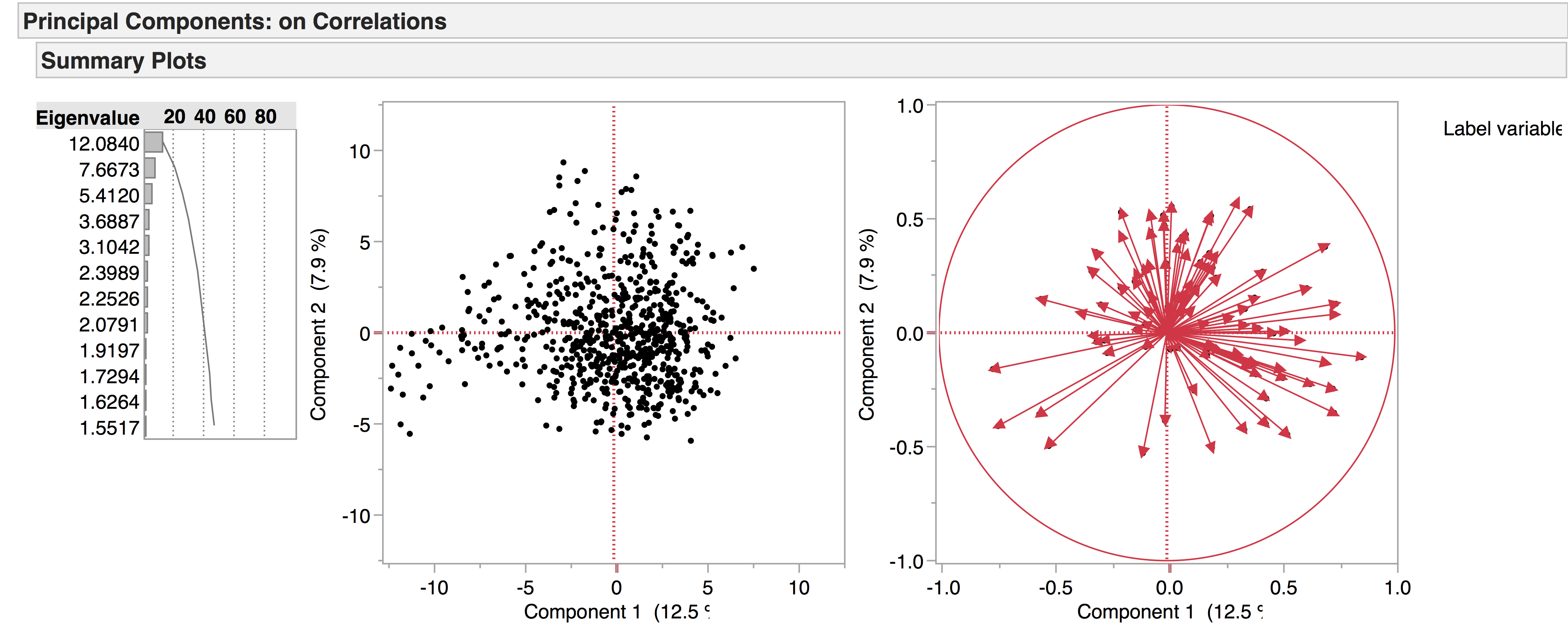
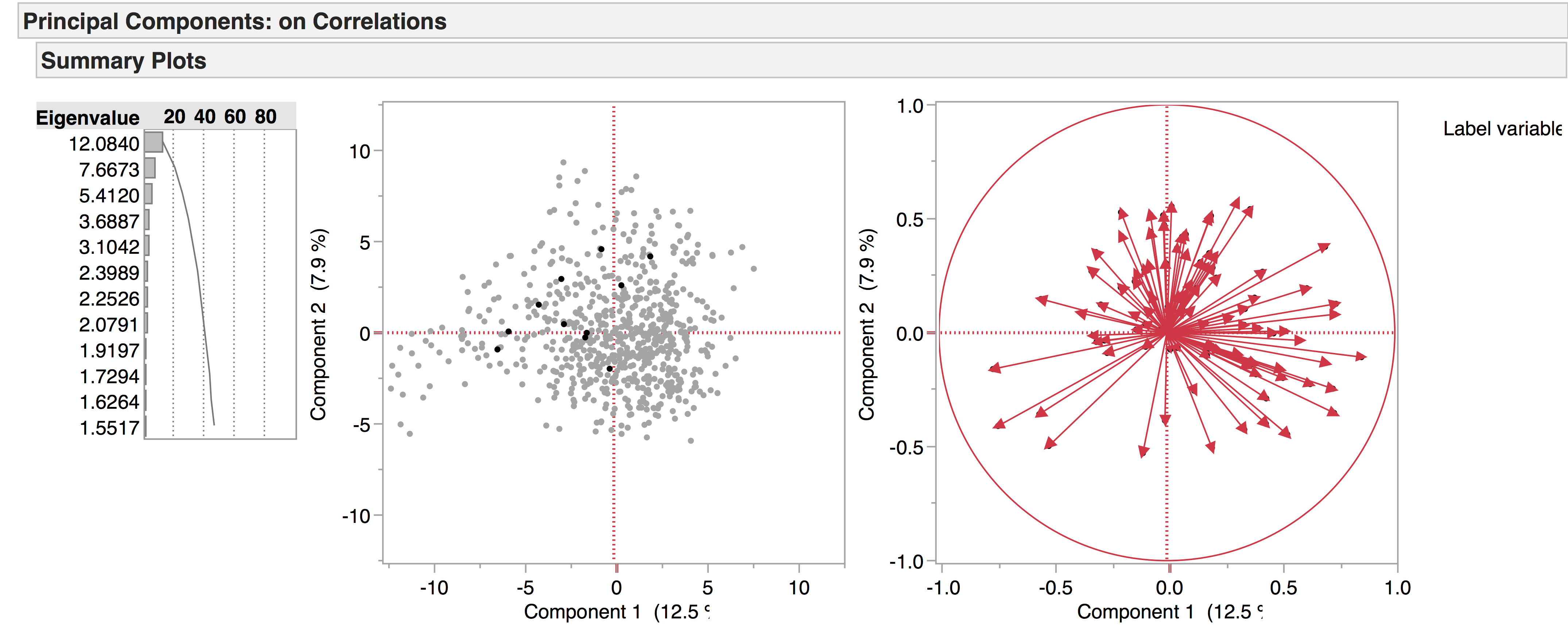
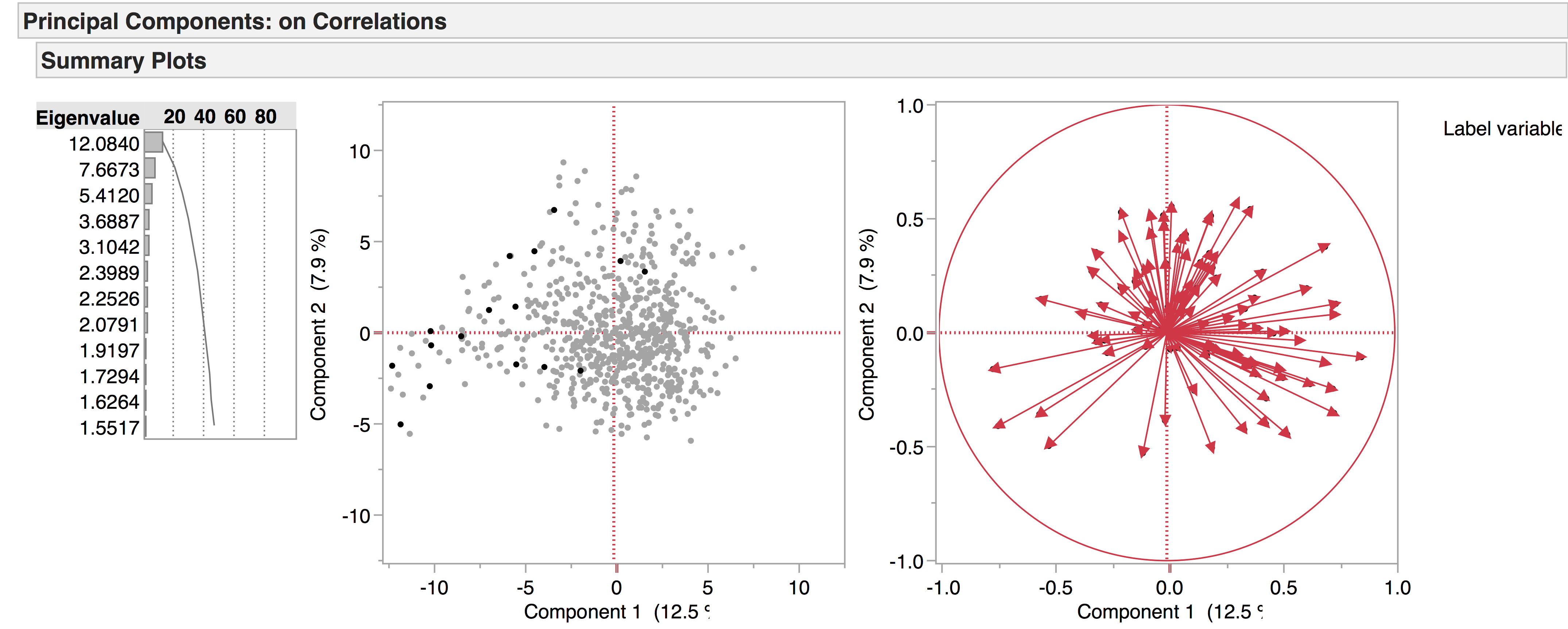
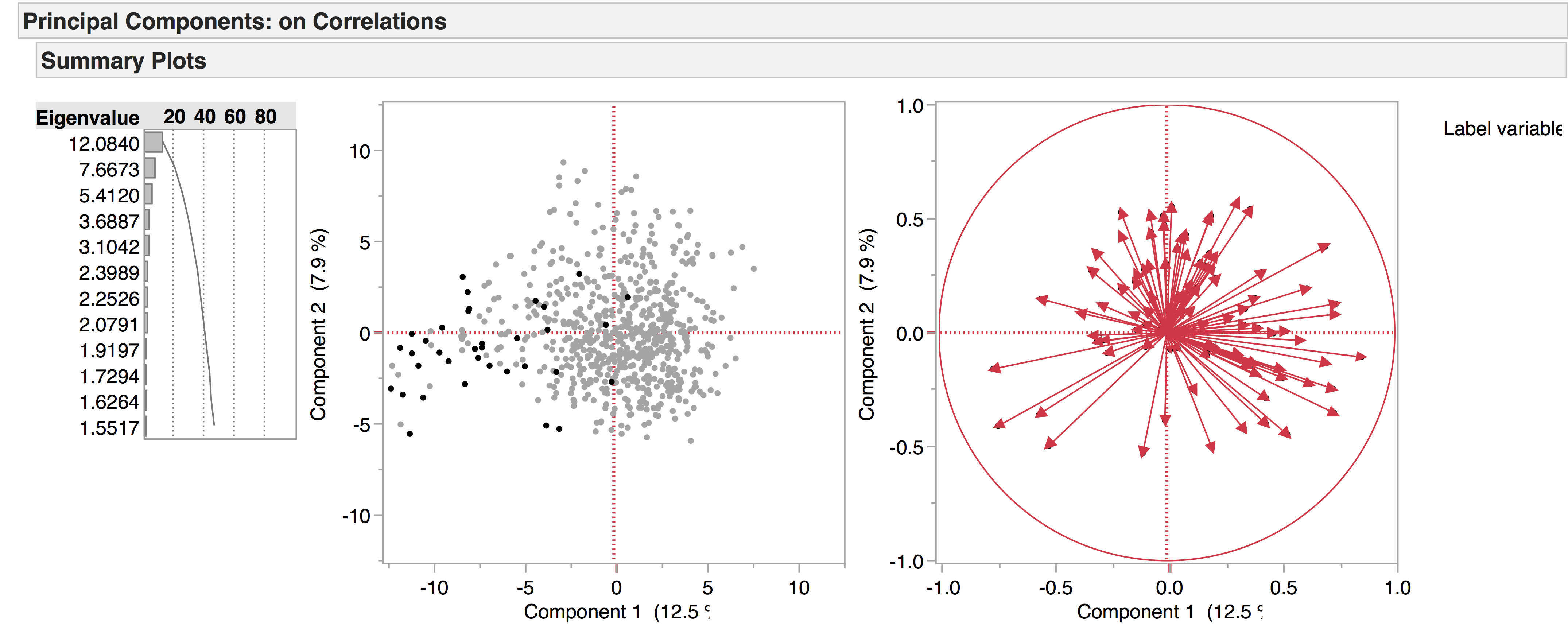
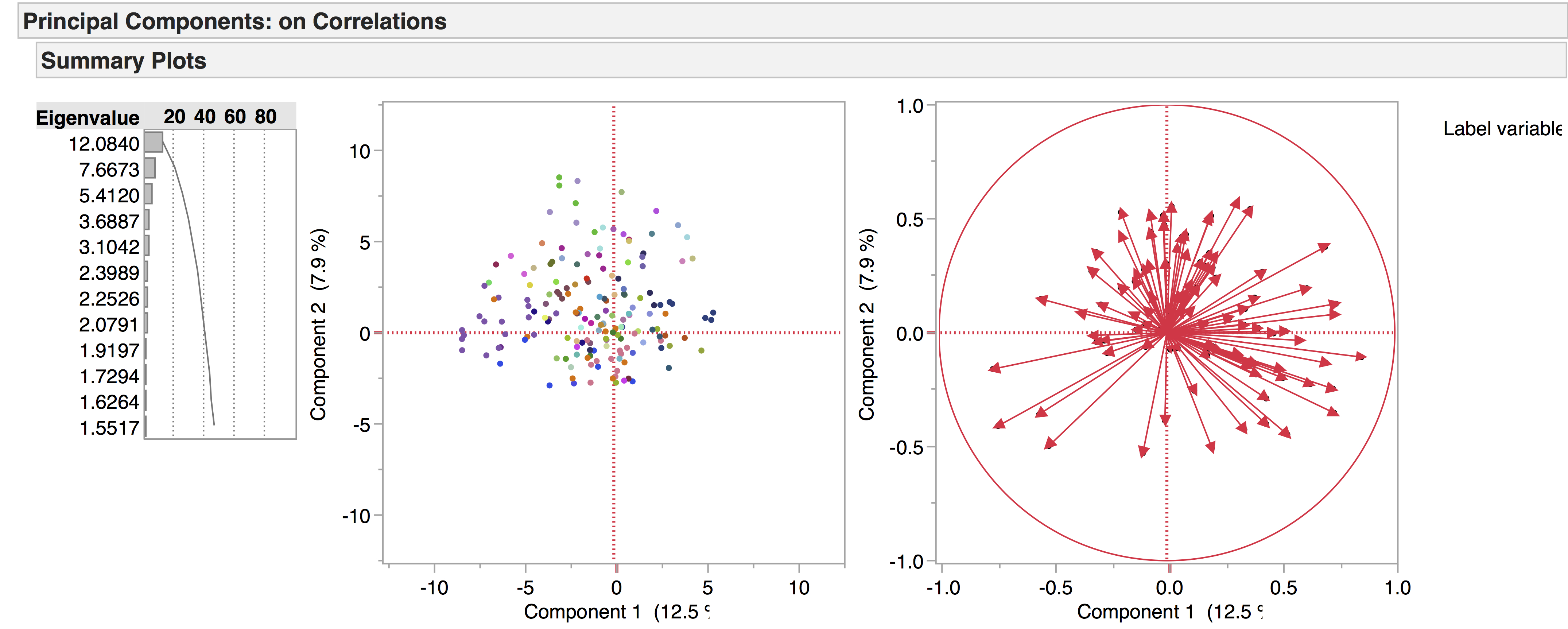
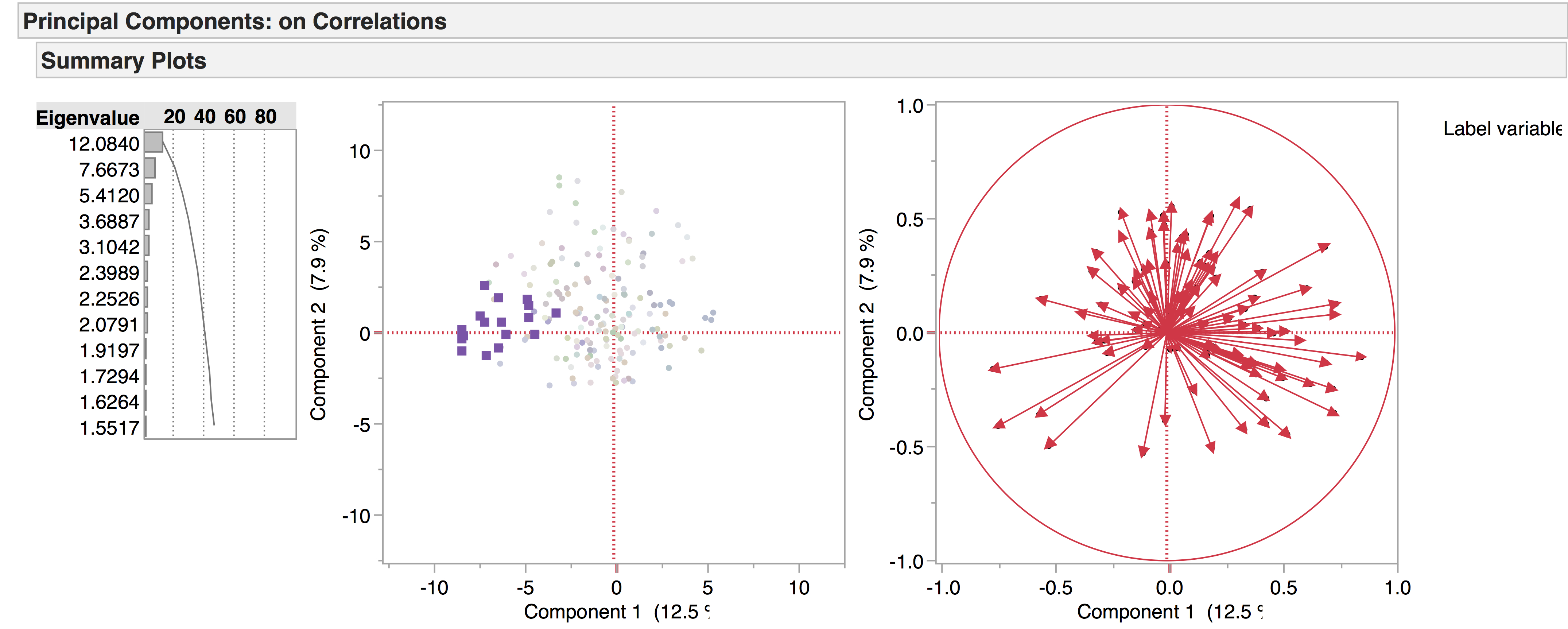
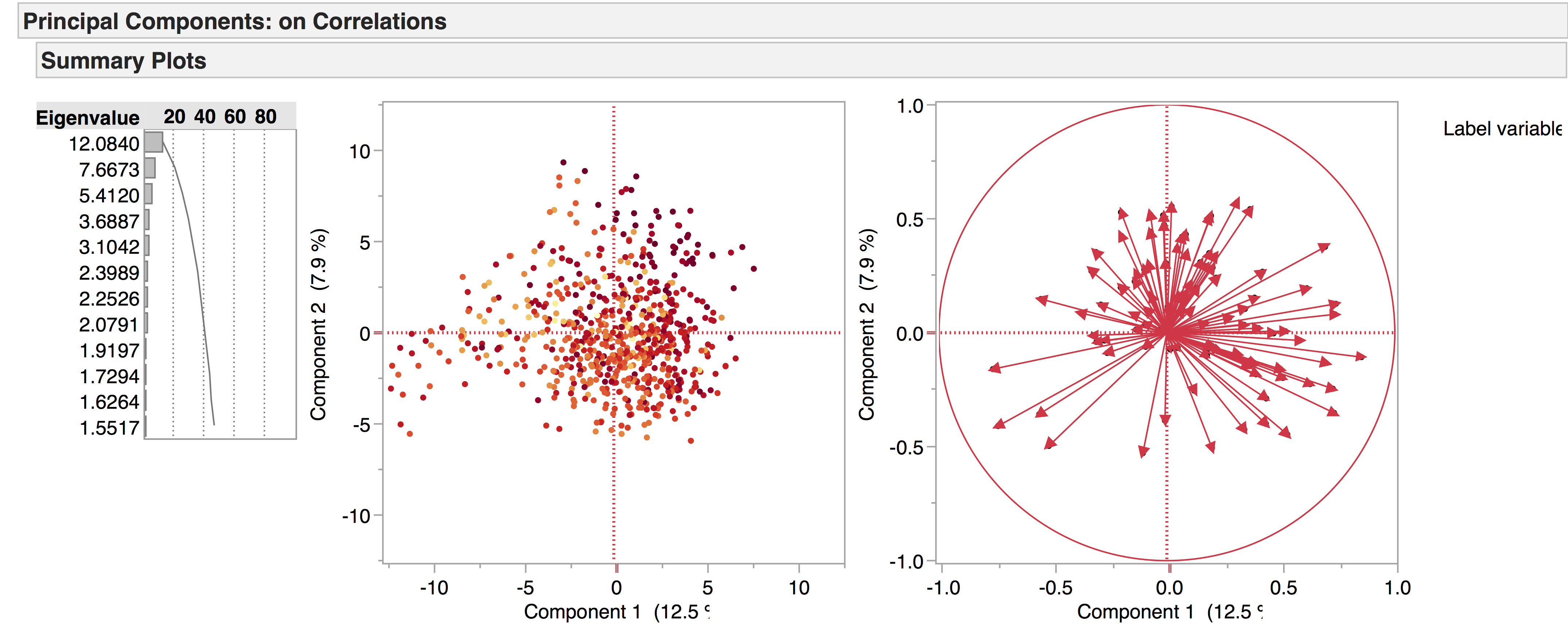
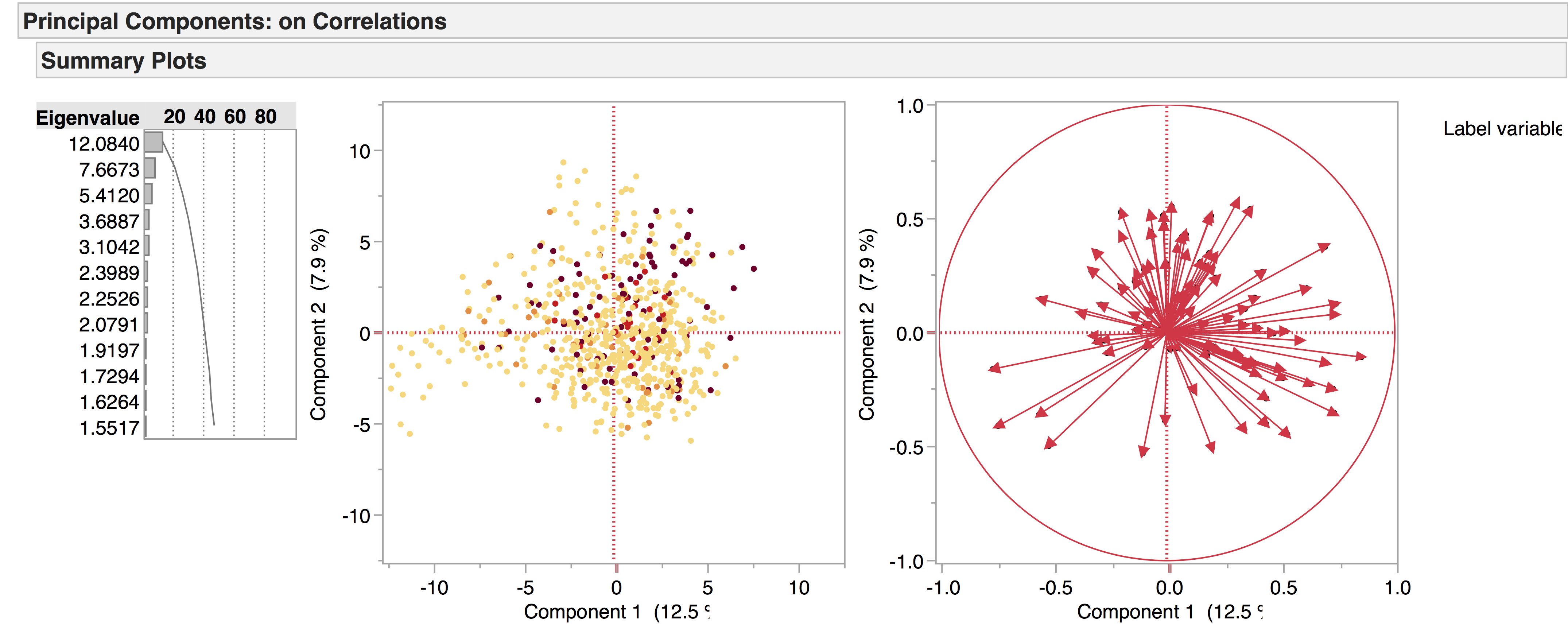
We’re currently working with two versions of our drama corpus: the earlier version contains 704 texts, while the later one has 554, the main distinction being that the later corpus has a four-way genre split – tragedy, comedy, tragicomedy, and history – while the earlier corpus also includes non-dramatic texts like dialogues, entertainments, interludes, and masques. Recently we’ve been doing PCA experiments with the 704 corpus to see what general patterns emerge, and to see how the non-dramatic genres pattern in the data. The following are a few of the PCA visualisations generated from this corpus, which provide a general overview of the data. We produced the diagrams here using JMP. The spreadsheets of the 704 and 554 corpora are included below as excel files – please note we are still working on the metadata.
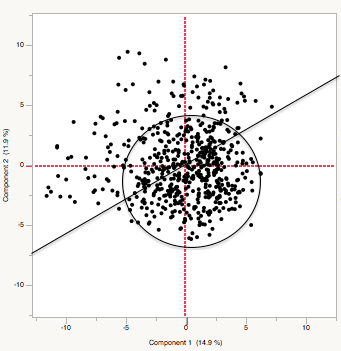
This is the complete data set visualised in PCA space. All 704 plays are included, but LATs with frequent zero values have been excluded.
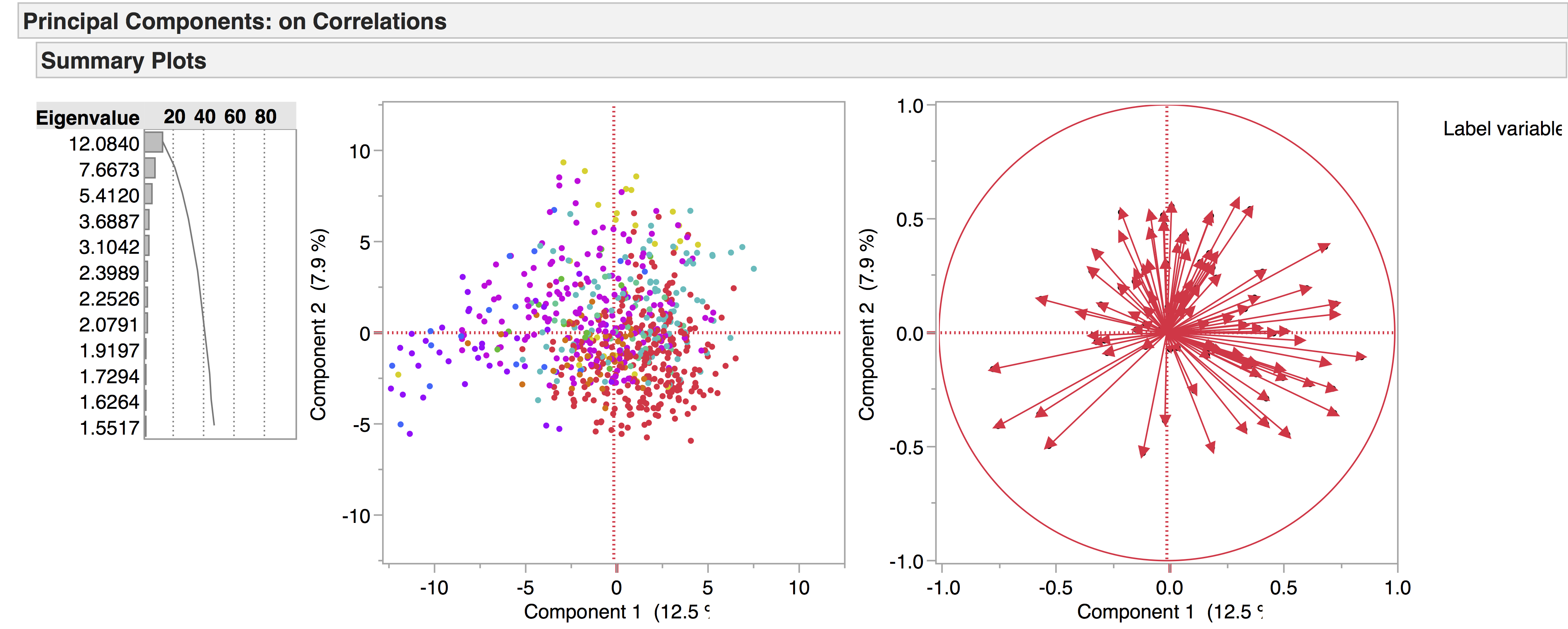
Genre:
If we highlight the genres, it looks like this:
Comedies = red
Dialogues = green
Entertainments = blue
Histories = orange
Interludes = blue-green
Masques = dark purple
Non-dramatics = mustard
Tragicomedies = dark turquoise
Tragedies = pink-purple
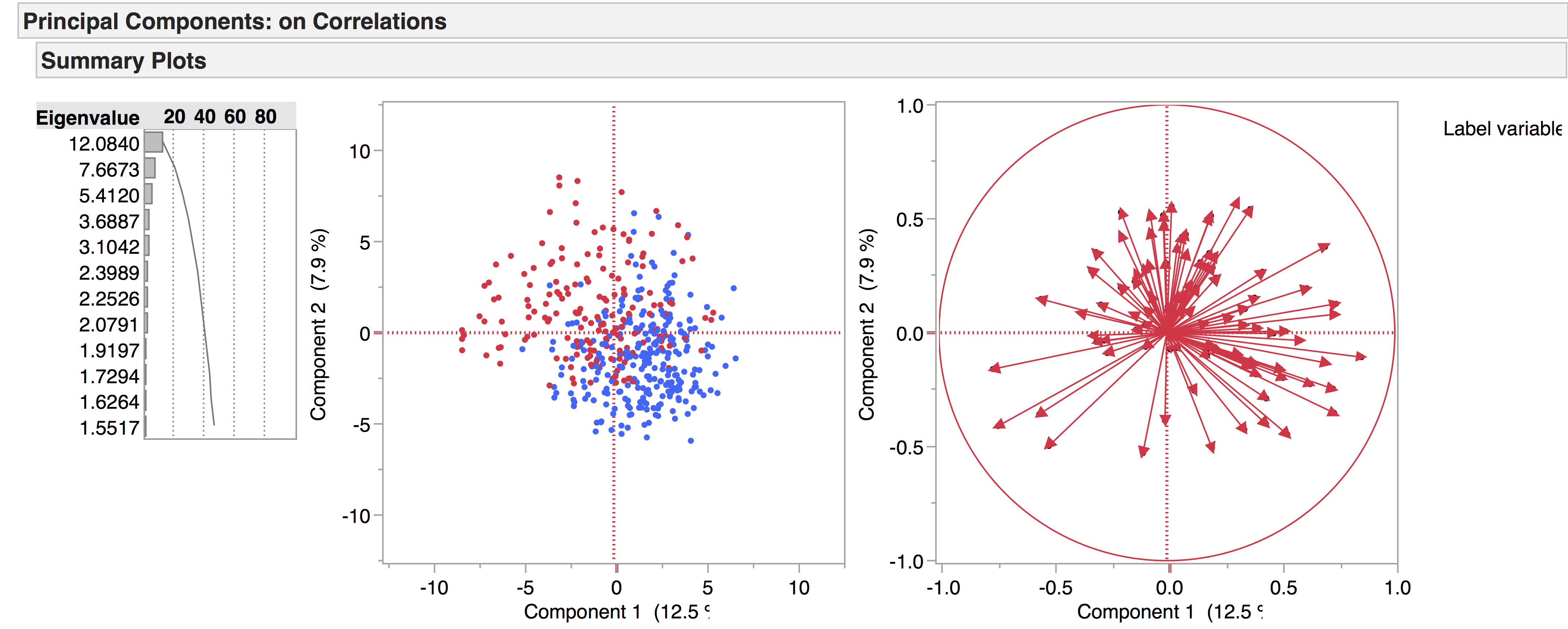
If we tease this out even more – hiding, but not excluding, the non-dramatic genres – there is a clear diagonal divide between tragedies (red) and comedies (blue):
[Michael Witmore, Jonathan Hope, and Michael Gleicher, forthcoming, ‘Digital Approaches to the Language of Shakespearean Tragedy’, in Michael Neill and David Schalkwyk, eds, The Oxford Handbook of ShakespeareanTragedy (Oxford)]
With tragicomedies (green) and histories (purple) falling in the middle:
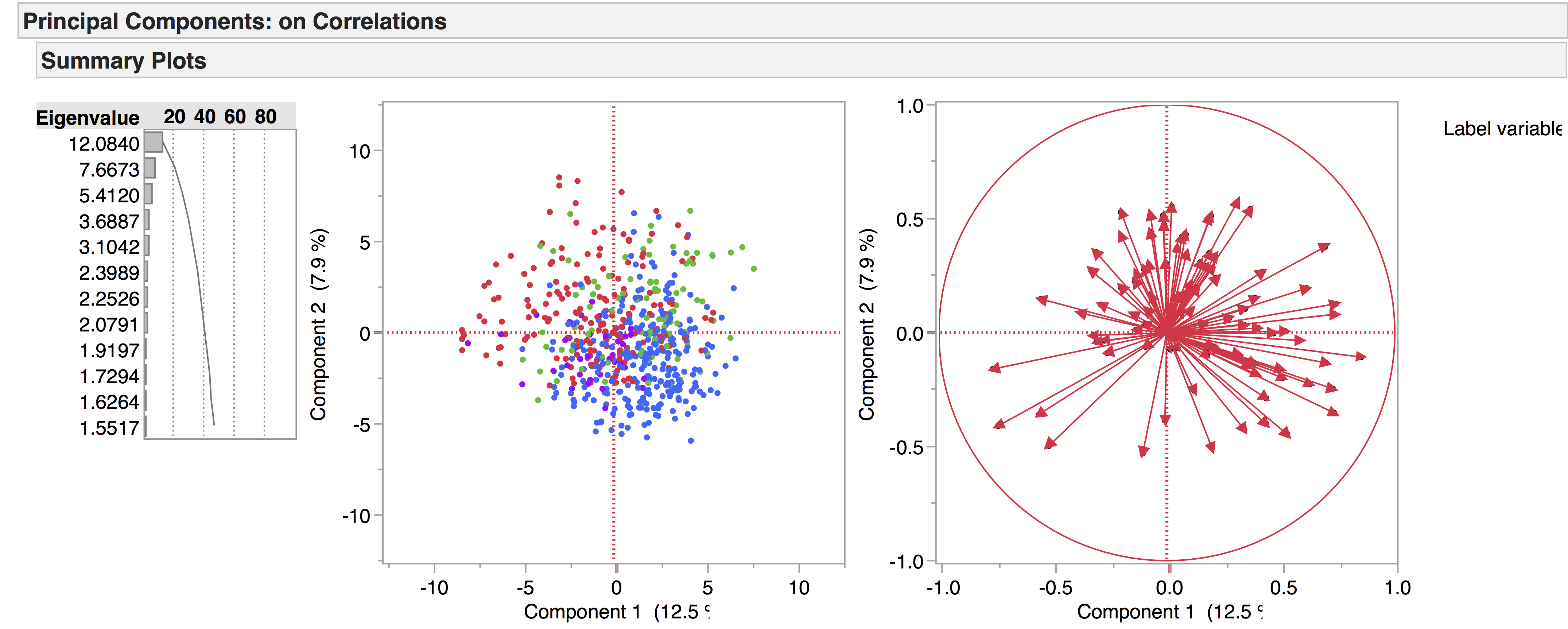
It seems that tragedies and comedies are characterised by sets of opposing LATs. The LATs associated with comedy are those capturing highly oral language behaviour, while those associated with tragedy capture negative language and psychological states. Tragicomedies and histories – although we have yet to investigate them in detail – seem to occupy an intermediate space. If we unhide the non-dramatic genres, we can see how they pattern in comparison.
In spite of their name, dialogues are not comprised of rapid exchanges (e.g. Oral Cues, Direct Address, First Person etc., the LATs which make up the comedic side of the PCA space) but instead have lengthy monologues, which might explain why they fall mostly on the side of the tragedies:
Entertainments do not seem to be linguistically similar to each other:
Interludes, on the other hand, seem to occupy a more tightly defined linguistic space:
Masques are pulled towards the left of the PCA space:
Authorship:
Docuscope was designed to identify genre, rather than authorship, so perhaps we should not be surprised that authorship comes through less clearly than genre in these initial trials. We should also bear in mind that there are only 9 genres in the corpus, compared to approximately 200 authors.
This, for example, shows only the tragedies – all other genres are hidden – and each author is represented by a different colour:
We get a clearer picture when considering a smaller group in relation to the whole – for example, one author compared to all the others. Take Seneca, for example – demonstrated by the purple squares:
From this we can deduce that Seneca’s tragedies are linguistically similar, as they are grouped tightly together.
Date:
The same applies for looking at date of writing across the corpus, with approximately 100 dates to consider.
This can be visualised on a continuous scale, e.g. the lighter the dot, the earlier the play; the darker the dot, the later the play. While this has a nice ‘heat map’ effect, it is difficult to interpret:
If we narrow this down to three groups of dates – early (red), central (yellow), and late (maroon) – it becomes a little easier to read. As with the Seneca example, the fewer factors there are to consider, the clearer the visualisations become:
The written version of a paper we gave in Paris last year (2013) has just been published by the Société française Shakespeare. Here is the paper (which is in English), and here are the citation details:
Pour citer cet article
Référence papier
Jonathan Hope et Michael Witmore, « Quantification and the language of later Shakespeare », Actes des congrès de la Société française Shakespeare, 31 | 2014, 123-149.
Référence électronique
Jonathan Hope et Michael Witmore, « Quantification and the language of later Shakespeare », Actes des congrès de la Société française Shakespeare [En ligne], 31 | 2014, mis en ligne le 29 avril 2014, consulté le 07 mai 2014. URL : http://shakespeare.revues.org/2830
591 Early Modern Dramas plotted in PCA space, with ‘core’ group circled and variation boundary marked (line)
American/Australian tour
In March-April 2014, I’ll be in the USA giving a series of talks and conference presentations based around Visualising English Print, and our other work. In June I’ll be in Newcastle, Australia for the very exciting Beyond Authorship symposium.
I’ll address a series of different themes in the talks, but I’ll use this page as a single resource for references, since they are all (in my head at least) related.
Some of the talks will be theoretical/state of the field; some will be specific demonstrations of tools. The common thread is something like, ‘what do we think we are doing?’.
Here’s a general introduction (there’s a list of venues afterwards).
1 Counting things
Quantification is certainly not new in literary criticism, but it is becoming more noticeable, and, perhaps, more central as critics analyse increasingly large corpora. The statistical tools we use to explore complex data sets (such as Shakespeare’s plays or 20,000 texts from EEBO-TCP) may appear like magical black boxes: feed in the numbers, print out the diagrams, wow your audience. But what is happening to our texts in those black boxes? Scary mathematical things we can’t hope to understand or critique?
I want to consider the nature of the transformations we perform on texts when we subject them to statistical analysis. To some extent this is analogous to ‘traditional’ literary criticism: we have a text, and we identify other texts that are similar or different to it:
How does Hamlet relate to other Early Modern tragedies?
This is a question equally suited to quantitative digital analysis, and traditional literary critical approaches. The ways we define and approach our terms will differ between the two modes, as will the evidence employed, but essentially both answers to this question would involve comparison and assessment of degrees of similarity and difference.
But there is also something very different to traditional literary criticism going on when we count things in texts and analyse the resulting spreadsheets – something literary scholars may feel unable to understand or critique. What exactly are we doing when we ‘project’ texts into hyper-dimensional spaces and use statistical tools to reduce those spaces down to something we can ‘read’ as humans?
Perhaps surprisingly, studying library architecture, book history, information science, and cataloguing systems may help us to think about this. Libraries organised by subject ‘project’ their books into three-dimensional space, so that books with similar content are found next to each other. Many statistical procedures function similarly, projecting books into hyper-dimensional spaces, and then using distance metrics to identify proximity and distance within the complex mathematical spaces our analysis creates.
Once we understand the geometry of statistical comparison, we can grasp the potential literary significance of the associations identified by counting – and we can begin to understand the difference between statistical significance and literary significance, and see that it is the job of the literary scholar, not the statistician, to decide on the latter. A result can be statistically significant, but of no interest in literary terms – and findings that do not qualify for statistical significance may be crucial for a literary argument.
2 Evidence
Ted Underwood has been posing lots of challenging, and productive, questions for literary scholars doing, or thinking about, digital work. Perhaps most significant is his recent suggestion that the digital causes problems for literary scholars, who are used to basing their arguments, and narratives, on ‘turning points’ and exceptions. Digital evidence, however, collected at scale, tells stories about continuity and gradual change. A possible implication of this is that the shift to digital analysis and evidence will fundamentally change the nature of literary studies, as we break away from a model that has arguably been with us only since the Romantics, and return (?) to one which traces long continuities in genre and form.
One way of posing this question: does the availability of large digital corpora and tools put us at the dawn of a new world, or are we just in for more (a lot more) of the same?
4 References and resources (these are grouped by topic)
(a) Statistics and hyper-dimensionality
Mick Alt, 1990, Exploring Hyperspace: A Non-Mathematical Explanation of Multivariate Analysis (London: McGraw-Hill) – the best book on hyper-dimensionality in statistical analysis: short, clear, and conceptually focussed
Most standard statistics textbooks give accounts of Principal Component Analysis (and Factor Analysis, to which it is closely related). We have found Andy Field, Discovering Statistics Using IBM SPSS Statistics: And Sex and Drugs and Rock and Roll (London: 2013, 4th ed.) useful.
Curiously, Early Modern drama, in the shape of Shakespeare, has a significant history in attempts to imagine hyper-dimensional worlds. E.A. Abbott, the author of A Shakespearian Grammar (London, 1870), also wrote Flatland: A Romance of Many Dimensions (London, 1884), an early science fiction work full of Shakespeare references and set in a two-dimensional universe.
The significance of Flatland to many who work in higher-dimensional geometry is shown by a recent scholarly edition sponsored by the Mathematical Association of America (Cambridge, 2010 – editors William F. Lindgren and Thomas F. Banchoff), and its use in physicist Lisa Randall’s account of theories of multiple dimensionality, Warped Passageways (New York, 2005), pages 11-28 (musical interlude: Dopplereffekt performing Calabi-Yau Space – which refers to a theory of hyper-dimensionality).
Flatland itself is the subject of a conceptual, dimensional transformation at the hands of poet/artist Derek Beaulieu:
Richard Gameson, 2006, ‘The medieval library (to c. 1450)’, Clare Sargent, 2006, ‘The early modern library (to c. 1640), and David McKitterick, 2006, ‘Libraries and the organisation of knowledge’, in Elizabeth Leedham-Green and Teressa Webber (eds), The Cambridge History of Libraries in Britain and Ireland vol. 1, ‘To 1640’, pp. 13-50, 51-65, and 592-615
Jane Rickard, 2013, ‘Imagining the early modern library: Ben Jonson and his contemporaries’ (unpublished paper presented at Strathclyde University Languages and Literatures Seminar)
On data, information management and catalogues:
Ann M. Blair, 2010, Too Much To Know: Managing Scholarly Information before the Modern Age (New Haven: Yale)
Markus Krajewski, 2011, Paper Machines: About Cards & Catalogs 1548-1929 (Cambridge, MSS: MIT) – on Conrad Gessner
Daniel Rosenberg, 2013, ‘Data before the Fact’, in Lisa Gitelman (ed), Raw Data is an Oxymoron (Cambridge, MSS: MIT), pp. 15-40 – combines digital analysis with a historicisation of the field, and the notion of ‘data’
(c) Ted Underwood and the digital future
Ted Underwood, 2013, Why Literary Periods Mattered: Historical Contrast and the Prestige of English Studies (Stanford) – especially chapter 6, ‘Digital Humanities and the Future of Literary History’, pp. 157-75 – on the strange commitment to discontinuity in literary studies, and the tendency of digital/at scale work to dissolve this into a picture of gradualism – Underwood cites his own work as an e.g. of the resistance scholars using quantification find within themselves to gradualism – and notes the temptation to seek fracture/outlier/turning point narrative
(also see Underwood’s discussion with Andrew Piper on Piper’s blog: http://bookwasthere.org/?p=1571 – balancing numbers and literary analysis – and Andrew Piper, 2012, Book There Was: Reading in Electronic Times (Chicago) – see chapter 7, ‘By The Numbers’ on computation, DH).
‘longue durée’ History – Underwood has suggested that historians are more comfortable than literary scholars with the ‘long view’ that tends to come with digital evidence, and David Armitage and Jo Guldi have been arguing that the digital is shifting history back to this mode:
David Armitage, 2012, ‘What’s the big idea? Intellectual history and the longue durée’, History of European Ideas, 38.4, pp. 493-507
(d) Overview/examples of Digital work:
Early Modern Digital Agendas was an NEH-funded Institute held at the Folger Shakespeare Library in 2013. The EMDA website has an extensive list of resources for Digital work focussed on the Early Modern period.
Text
An excellent account of starting text-analytic work by a newcomer to the field:
An example of an info-heavy, ‘reference’ site that makes excellent use of maps – The Museum of the Scottish Shale Oil Industry (!): http://www.scottishshale.co.uk
Bpi1700 makes a database of ‘thousands’ of prints and book illustrations available ‘in fully-searchable form’. However, searching is text-based (see http://www.bpi1700.org.uk/jsp/)
Development halted? ‘Although the main development work has been completed, improvements will continue to be made from time to time. If you have problems or suggestions please contact the project (see the ‘contact’ page).’ http://www.bpi1700.org.uk/index.html
The Ukiyo-e Search site is an amazing resource that represents something genuinely new (rather than just an extension of previously existing word-based catalogue searching), in that it allows searching via an uploaded image. For example, a researcher can upload a phone-image of a print she discovers in a library, and see if the same/similar prints have been previously described, and how many other libraries have copies or versions of the print. The search is ‘fuzzy’ and will often detect different states of altered woodblocks. [Thanks to @GilesBergel for the news that a similar functionality is coming to the Bodleian Ballads project.]
The Ukiyo-e site was created by one person, John Resig, an enthusiast for Ukiyo-e, who saw the need for the site as a research tool. Development and expansion on-going.
‘The database currently contains over 213,000 prints from 24 institutions and, as of September 2013, has received 3.4 million page views from 150,000 people.’ http://ukiyo-e.org/about
And finally, pictures of my kittens Arthur and Gracie, who will feature in the talks:
Arthur can work a computer (he wrote the title of this post).
Many intriguing things to respond to in recent postings by Jonathan and Heather, but I’ll begin with the observation that chimes most clearly with the work we’ve been doing in the rehearsal room this week. The strongest note of recognition comes from the increased usage of terms of address that Jonathan has observed.
To reiterate the point from Jonathan’s post, there is a fairly tight social group presented in Much Ado About Nothing: although we move through the social scale from a don, the Prince of Aragon, down to Hugh Oatcake of the watch, the characters we meet in the play seem fairly comfortable interacting with one another. By that I mean we don’t see any obvious rift between social groups, there are no real strangers in the midst, no-one truly flouting convention, no licensed fool (unless you count Beatrice and Benedick) and no magical creatures or gods to challenge human hubris. Cupid seems to get name-checked as often as any Christian God and in fact, while we are in that realm, it’s interesting to note that there seems to be very little sense of any higher power at all (save for a few Biblical references and the presence of a fairly worldly Friar). What we do have in our story is Don Pedro of Aragon and a small group of soldiers, who arrive at the home of Leonato and his family. They agree to stay a month and everyone seems reasonably comfortable with this arrangement. The ensuing marriages, friendships, confidences and liaisons (actual and possible) during their stay seem ‘easy’, in the sense that they cause no social ructions or conflicts when they are proposed, discussed or realised.
What we see, instead of a particularly broad social sweep, is that the narrowness of this social group seems to create a culture of anxiety, one of jealousy and rivalry, a place of comparison, ambition and social climbing. Claudio’s new honours from the wars are glories born of Don John’s overthrow (potentially even thwarting an attempted coup or challenge to the Prince’s authority), and it seems that this resentment fuels, if not causes, Don John’s actions against Claudio in the thwarting of his marriage. His ally in the plotting, Borachio, is branded as “deformed” (dressing in a way he should not, namely above his social standing) for “going up and down like a gentleman”. Then of course there are the many other disguises and tricks that are enacted during the play, where characters take on the guise of another person, which from the first creates the chief anxiety in the world of the play, that of being supplanted or more specifically cuckolded.
This for the most part is the great big nothing there’s such an ado about. Claudio – even though Don Pedro (his Prince, companion and friend) swears he will woo Hero ‘in his name’, is quick to believe that this friend has actually wooed for himself and is seen to be “of that jealous complexion”. It is therefore no surprise to me that in this world of demob happy men where status is in a state of flux, people are keen to lock down identity where they can and name their roles to one another, to be known by their status or familial connection: Prince, Count, Cousin, Brother, Signor, Father, Master Constable, Friend.
Even in the town scenes where we meet the watch (or more specifically the Prince’s Watch), where the social scale is further compacted, there are tussles over who’s who. To write and read gives one some added status, but beyond this – and perhaps the respect that comes with age – there is no end of wrangling with plenty of intricacies amongst the sirs, sirrahs, friends, neighbours and the corrective “I am a gentleman” from Conrad. These can be played and received with varying degrees on sincerity or mocking of course, as we would today with the use of ‘mate’.
For Beatrice and Benedick and their dance toward marriage, they separately name and reiterate their roles as confirmed batchelors during the first half of the play and spend the second half working out how they might reinvent themselves if they volte face from those roles. Even so, with the fairly constant titles of Lady Beatrice and Signor Benedick many of their verbal parries involve name-calling or rechristening one another – Signor Mountanto, Lady Disdain, the Prince’s Jester – so that their playfulness parodies the society around them.
#MuchAdo #AboutData update 3
The cast are now well into rehearsals, and you can see photos on @PallantPallant‘s twitter feed.
Meanwhile the data miners are about to get on planes to go to the Renaissance Society of America meeting in New York (#rsa14). Here’s a contribution from @heatherfro on the big pronoun question:
HF:
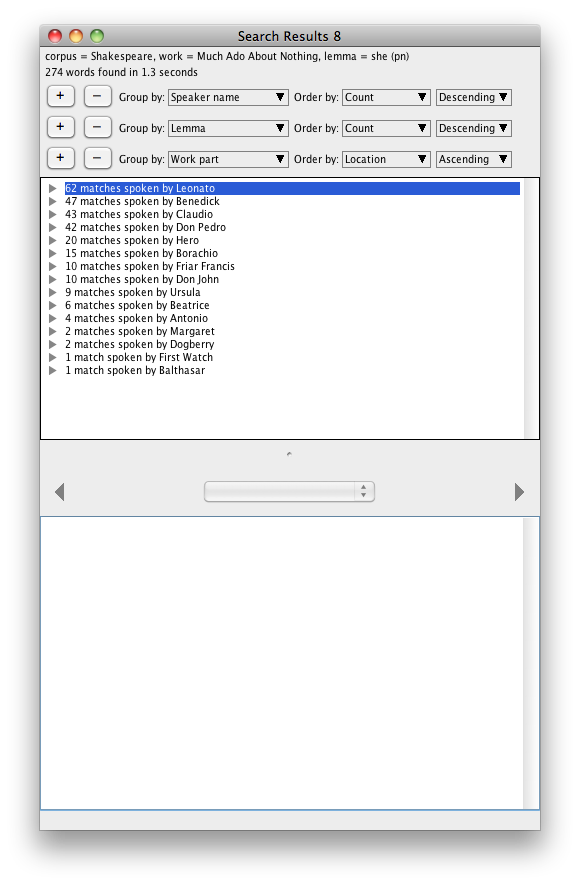
I’m still thinking about the best way to measure characters’ speech by gender, which is turning out to be a very interesting question. In the meantime, I did some poking around the Wordhoard system to see if I could find anything else about your pronoun question, and I think I have.
Leonato, not Benedick, uses the lemma she the most out of all the characters:
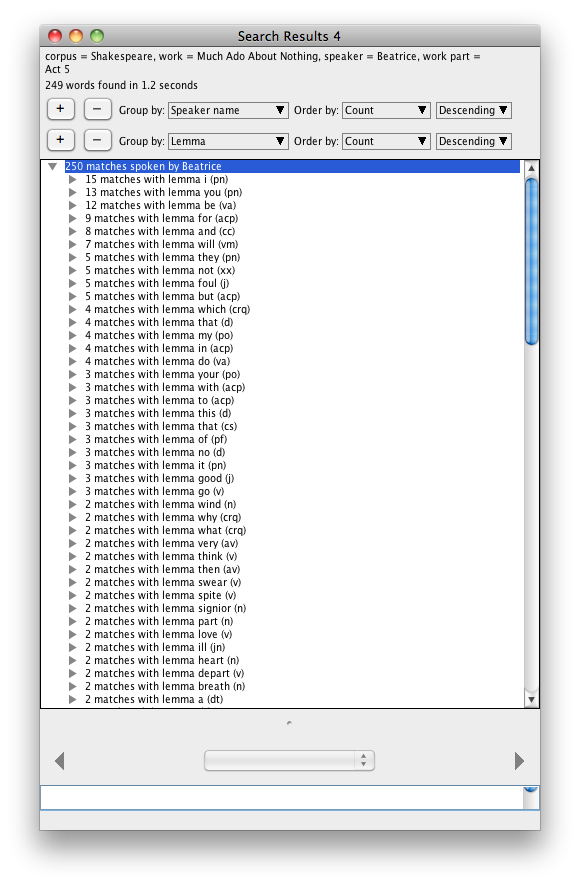
Beatrice has a very big decline of her use of the lemma he in the play – II.i has the most instances, and by the end of the play she doesn’t use the lemma at all…
In Act 5 she mostly talks about herself:
This is really interesting for me, though I can’t yet explain why – I suspect there’s something to be said about agency here.
After much I/me discussion between Benedick and Beatrice, we want her to be ending with Benedick by saying we, she doesn’t say we after Act Two, Scene I (2.i.45, 2.1.139; previously there’s one instance of we in 1.i.54). Benedick is the one to say it**, declaring:
Benedick: Come, come, we are friends: let’s have a dance ere we are married, that we may lighten our own hearts and our wives’ heels.
(5.iv.117-118) and this raises more agency questions for me … I wonder what Emma can say about Beatrice’s role, especially at the end of the play?
**Note by JH: my reading of these lines is that the we here is Benedick and Claudio, not Benedick and Beratrice – though the point stands, as Benedick uses a plural pronoun to refer to himself and Beatrice at 5.iv.91-2:
A miracle! Here’s our own hands against our hearts!
He immediately shifts back into the singular as the two re-establish their witty antagonism:
Come, I will have thee, but by this light I take thee for pity.
And Beatrice, perhaps true to character, never shifts:
Beatrice: I would not deny you, but by this good day I yield upon great persuasion – and partly to save your life, for I was told you were in a consumption.
#MuchAdo #AboutData update 2 (scroll down for the intro to these posts)
The previous finding was about the pronoun ‘she’. This one also uses Log-likelihood to identify words used far more frequently in Much Ado than they are in Shakespeare’s other work.
While ‘she’ is the highest scoring word on Log-likelihood, maybe more striking is a run of words that come next:
signor
prince
count
lady
don
cousin
brother
daughter
Aside from the last two, these are all *very* significantly raised: and they clearly share a function/meaning in that they are terms of address. Some (signor, don) might be said to be plot-related, in that they may reflect the particular setting of Much Ado – but that’s not true for most, and the finding is very robust (they are all strongly raised, even those not associated with this particular setting).
My initial explanation for this is that this tracks a relatively unusual format Much Ado has (unusual compared to Shakespeare’s other work): i.e., it depicts a relatively large group of relatively equal social status interacting relatively equally (note the relativelies!) – and does so in lots of prose. My impression is that most other plays focus on smaller groups, and feature interactions up and down the social scale more. There’s an unusually ‘flat’ social structure in Much Ado – and this is reflected in the profusion of address terms. I think there may be a comparison with City comedy to be made here, but that’s for later posts.
I wonder if Emma and the rest of the cast have noticed anything that chimes with this?
Method: this test looks at word frequency in the play, but not simple frequency (which is often not that interesting: words like ‘the’ and ‘and’ are the most frequent in every play).
What it looks for is words that are used more frequently or less frequently in the play than you would expect given Shakespeare’s usage in his other work. The program counts the totals for each word in the play (= ‘the analysis sample’) and compares them to the totals for the same words in all of Shakespeare (= ‘the reference sample’).
It looks for big rises or falls, and adjusts these against the overall frequency of the word to give a score for how unusual the result is, and how likely it is to be due to chance or not (significance). Results unlikely to be due to chance are given stars: highest rating is four stars.
In this test I excluded names, since it isn’t very interesting to find that Shakespeare uses Beatrice more in Much Ado than he does in his other work.
Standout findings
Finding 1.1
The word* with the biggest shift in usage compared to Shakespeare’s norm is the pronoun ‘she/her’ – with a significance rating of four stars, it is raised in this play way over its frequency elsewhere. To give you a sense of how much it is raised, Shakespeare normally uses ‘she’ 53 times every 10,000 words. In Much Ado, he uses it 131 times every 10,000 words.
There are just over 21,000 words in Much Ado. Let’s call that 20,000 for simplicity. This means Shakespeare uses ‘she’ around 262 times in the play. If he was behaving normally, he’d use it 106 times.
This is a big shift – an already frequent word is used two and a half times as often.
Why?
It is tempting to wonder if female characters are more prominent in Much Ado: are there more of them? Do they speak more lines? (We’ll ask Heather Froehlich if she has suggestions re this.)
But this result isn’t necessarily telling us that. What it tells us is that women are referred to more frequently in this play. Maybe it’s just that men talk about women a lot – or maybe men and women talk about women.
Anyway: there’s the first finding. Now over to Emma in the rehearsal room…
*I did this search on ‘lemma’, which automatically includes different forms of the ‘same’ word – so ‘she’ and ‘her’ are counted together.
We’ve posted in the past about advising actors at Shakespeare’s Globe in London on the language of plays they are rehearsing. This is the first in an experimental series of short posts building on that process.
I’m going to be running some analyses on the language of Much Ado About Nothing and discussing the results with Emma Pallant (@PallantPallant), who will be playing Beatrice in a Globe touring production this year (2014).
Emma is an outstanding, and really thoughtful, actor (who crops up on the cover of this book on women making Shakespeare) -so whether I come up with anything interesting or not, the production is sure to be worth seeing. If you are in the UK, or Austria, there’s a chance the production will be close to you at some point in spring/summer (details of venues and ticket booking here).
We’ll also tweet about the data, using the hashtags #MuchAdo #AboutData
As a teaser/taster, click on the image at the top of this post for a quick overview of the distribution of the word ‘she’ across the play. Notice anything?