The written version of a paper we gave in Paris last year (2013) has just been published by the Société française Shakespeare. Here is the paper (which is in English), and here are the citation details:
Pour citer cet article
Référence papier
Jonathan Hope et Michael Witmore, « Quantification and the language of later Shakespeare », Actes des congrès de la Société française Shakespeare, 31 | 2014, 123-149.
Référence électronique
Jonathan Hope et Michael Witmore, « Quantification and the language of later Shakespeare », Actes des congrès de la Société française Shakespeare [En ligne], 31 | 2014, mis en ligne le 29 avril 2014, consulté le 07 mai 2014. URL : http://shakespeare.revues.org/2830
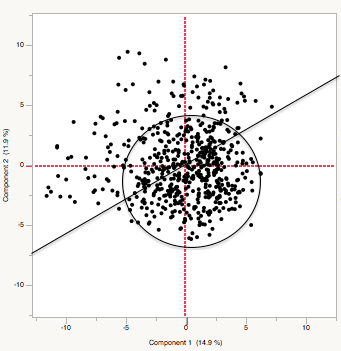
591 Early Modern Dramas plotted in PCA space, with ‘core’ group circled and variation boundary marked (line)
American/Australian tour
In March-April 2014, I’ll be in the USA giving a series of talks and conference presentations based around Visualising English Print, and our other work. In June I’ll be in Newcastle, Australia for the very exciting Beyond Authorship symposium.
I’ll address a series of different themes in the talks, but I’ll use this page as a single resource for references, since they are all (in my head at least) related.
Some of the talks will be theoretical/state of the field; some will be specific demonstrations of tools. The common thread is something like, ‘what do we think we are doing?’.
Here’s a general introduction (there’s a list of venues afterwards).
1 Counting things
Quantification is certainly not new in literary criticism, but it is becoming more noticeable, and, perhaps, more central as critics analyse increasingly large corpora. The statistical tools we use to explore complex data sets (such as Shakespeare’s plays or 20,000 texts from EEBO-TCP) may appear like magical black boxes: feed in the numbers, print out the diagrams, wow your audience. But what is happening to our texts in those black boxes? Scary mathematical things we can’t hope to understand or critique?
I want to consider the nature of the transformations we perform on texts when we subject them to statistical analysis. To some extent this is analogous to ‘traditional’ literary criticism: we have a text, and we identify other texts that are similar or different to it:
How does Hamlet relate to other Early Modern tragedies?
This is a question equally suited to quantitative digital analysis, and traditional literary critical approaches. The ways we define and approach our terms will differ between the two modes, as will the evidence employed, but essentially both answers to this question would involve comparison and assessment of degrees of similarity and difference.
But there is also something very different to traditional literary criticism going on when we count things in texts and analyse the resulting spreadsheets – something literary scholars may feel unable to understand or critique. What exactly are we doing when we ‘project’ texts into hyper-dimensional spaces and use statistical tools to reduce those spaces down to something we can ‘read’ as humans?
Perhaps surprisingly, studying library architecture, book history, information science, and cataloguing systems may help us to think about this. Libraries organised by subject ‘project’ their books into three-dimensional space, so that books with similar content are found next to each other. Many statistical procedures function similarly, projecting books into hyper-dimensional spaces, and then using distance metrics to identify proximity and distance within the complex mathematical spaces our analysis creates.
Once we understand the geometry of statistical comparison, we can grasp the potential literary significance of the associations identified by counting – and we can begin to understand the difference between statistical significance and literary significance, and see that it is the job of the literary scholar, not the statistician, to decide on the latter. A result can be statistically significant, but of no interest in literary terms – and findings that do not qualify for statistical significance may be crucial for a literary argument.
2 Evidence
Ted Underwood has been posing lots of challenging, and productive, questions for literary scholars doing, or thinking about, digital work. Perhaps most significant is his recent suggestion that the digital causes problems for literary scholars, who are used to basing their arguments, and narratives, on ‘turning points’ and exceptions. Digital evidence, however, collected at scale, tells stories about continuity and gradual change. A possible implication of this is that the shift to digital analysis and evidence will fundamentally change the nature of literary studies, as we break away from a model that has arguably been with us only since the Romantics, and return (?) to one which traces long continuities in genre and form.
One way of posing this question: does the availability of large digital corpora and tools put us at the dawn of a new world, or are we just in for more (a lot more) of the same?
4 References and resources (these are grouped by topic)
(a) Statistics and hyper-dimensionality
Mick Alt, 1990, Exploring Hyperspace: A Non-Mathematical Explanation of Multivariate Analysis (London: McGraw-Hill) – the best book on hyper-dimensionality in statistical analysis: short, clear, and conceptually focussed
Most standard statistics textbooks give accounts of Principal Component Analysis (and Factor Analysis, to which it is closely related). We have found Andy Field, Discovering Statistics Using IBM SPSS Statistics: And Sex and Drugs and Rock and Roll (London: 2013, 4th ed.) useful.
Curiously, Early Modern drama, in the shape of Shakespeare, has a significant history in attempts to imagine hyper-dimensional worlds. E.A. Abbott, the author of A Shakespearian Grammar (London, 1870), also wrote Flatland: A Romance of Many Dimensions (London, 1884), an early science fiction work full of Shakespeare references and set in a two-dimensional universe.
The significance of Flatland to many who work in higher-dimensional geometry is shown by a recent scholarly edition sponsored by the Mathematical Association of America (Cambridge, 2010 – editors William F. Lindgren and Thomas F. Banchoff), and its use in physicist Lisa Randall’s account of theories of multiple dimensionality, Warped Passageways (New York, 2005), pages 11-28 (musical interlude: Dopplereffekt performing Calabi-Yau Space – which refers to a theory of hyper-dimensionality).
Flatland itself is the subject of a conceptual, dimensional transformation at the hands of poet/artist Derek Beaulieu:
Richard Gameson, 2006, ‘The medieval library (to c. 1450)’, Clare Sargent, 2006, ‘The early modern library (to c. 1640), and David McKitterick, 2006, ‘Libraries and the organisation of knowledge’, in Elizabeth Leedham-Green and Teressa Webber (eds), The Cambridge History of Libraries in Britain and Ireland vol. 1, ‘To 1640’, pp. 13-50, 51-65, and 592-615
Jane Rickard, 2013, ‘Imagining the early modern library: Ben Jonson and his contemporaries’ (unpublished paper presented at Strathclyde University Languages and Literatures Seminar)
On data, information management and catalogues:
Ann M. Blair, 2010, Too Much To Know: Managing Scholarly Information before the Modern Age (New Haven: Yale)
Markus Krajewski, 2011, Paper Machines: About Cards & Catalogs 1548-1929 (Cambridge, MSS: MIT) – on Conrad Gessner
Daniel Rosenberg, 2013, ‘Data before the Fact’, in Lisa Gitelman (ed), Raw Data is an Oxymoron (Cambridge, MSS: MIT), pp. 15-40 – combines digital analysis with a historicisation of the field, and the notion of ‘data’
(c) Ted Underwood and the digital future
Ted Underwood, 2013, Why Literary Periods Mattered: Historical Contrast and the Prestige of English Studies (Stanford) – especially chapter 6, ‘Digital Humanities and the Future of Literary History’, pp. 157-75 – on the strange commitment to discontinuity in literary studies, and the tendency of digital/at scale work to dissolve this into a picture of gradualism – Underwood cites his own work as an e.g. of the resistance scholars using quantification find within themselves to gradualism – and notes the temptation to seek fracture/outlier/turning point narrative
(also see Underwood’s discussion with Andrew Piper on Piper’s blog: http://bookwasthere.org/?p=1571 – balancing numbers and literary analysis – and Andrew Piper, 2012, Book There Was: Reading in Electronic Times (Chicago) – see chapter 7, ‘By The Numbers’ on computation, DH).
‘longue durée’ History – Underwood has suggested that historians are more comfortable than literary scholars with the ‘long view’ that tends to come with digital evidence, and David Armitage and Jo Guldi have been arguing that the digital is shifting history back to this mode:
David Armitage, 2012, ‘What’s the big idea? Intellectual history and the longue durée’, History of European Ideas, 38.4, pp. 493-507
(d) Overview/examples of Digital work:
Early Modern Digital Agendas was an NEH-funded Institute held at the Folger Shakespeare Library in 2013. The EMDA website has an extensive list of resources for Digital work focussed on the Early Modern period.
Text
An excellent account of starting text-analytic work by a newcomer to the field:
An example of an info-heavy, ‘reference’ site that makes excellent use of maps – The Museum of the Scottish Shale Oil Industry (!): http://www.scottishshale.co.uk
Bpi1700 makes a database of ‘thousands’ of prints and book illustrations available ‘in fully-searchable form’. However, searching is text-based (see http://www.bpi1700.org.uk/jsp/)
Development halted? ‘Although the main development work has been completed, improvements will continue to be made from time to time. If you have problems or suggestions please contact the project (see the ‘contact’ page).’ http://www.bpi1700.org.uk/index.html
The Ukiyo-e Search site is an amazing resource that represents something genuinely new (rather than just an extension of previously existing word-based catalogue searching), in that it allows searching via an uploaded image. For example, a researcher can upload a phone-image of a print she discovers in a library, and see if the same/similar prints have been previously described, and how many other libraries have copies or versions of the print. The search is ‘fuzzy’ and will often detect different states of altered woodblocks. [Thanks to @GilesBergel for the news that a similar functionality is coming to the Bodleian Ballads project.]
The Ukiyo-e site was created by one person, John Resig, an enthusiast for Ukiyo-e, who saw the need for the site as a research tool. Development and expansion on-going.
‘The database currently contains over 213,000 prints from 24 institutions and, as of September 2013, has received 3.4 million page views from 150,000 people.’ http://ukiyo-e.org/about
And finally, pictures of my kittens Arthur and Gracie, who will feature in the talks:
Arthur can work a computer (he wrote the title of this post).
When Jonathan Hope and I did our initial Docuscope study of over 300 Renaissance plays, we found Shakespeare’s plays clustering together for the most part. One explanation for this clustering was that it was caused by something distinctive in Shakespeare’s writing, and that this authorial signature becomes visible in the same way genre does—at the level of the sentence. Indeed, in our first approach to this larger dataset (one we’d assembled from the Globe Shakespeare and Martin Mueller’s semi-algorithmically modernized TCP plays), we thought that authorship was overriding genre as source of patterned variance.
But everything which goes into the dataset also comes out. And in this case, it was editorial difference that was helping to isolate Shakespeare’s plays. When we did a further study of the clusters containing works by Shakespeare, we noticed that their elevated levels of two different LATs that dealt with punctuation – TimeDate and LanguageReference – was an artifact of hand modernization.
Several contracted items from the Globe/Moby Shakespeare edition, tagged as Language Reference Strings by Docuscope
The variability in early modern orthography is well known, and we also know that there were many ways of punctuating early modern texts. (In the case of Shakespeare’s plays, we assume that most of the punctuation originated with the compositors who set up the text in the printhouse rather than Shakespeare himself.) But when the Globe editors modernized their sources in the nineteenth century, they consistently applied certain rules of punctuation that skew Docuscope’s counts when these texts (as a group) were compared with the more varied punctuation to be found in the TCP texts. Sequences that were dealt with consistently in the Globe texts – for example, contractions such as [’tis] or [’twas] or [o’clock] – were being handled much more variously in the original-spelling texts that Martin Mueller was modernizing. (He was only modernizing words in his procedure.)
So, the punctuation was a tip off, increasing the chances that Shakespeare’s plays would cluster together.
We now have the ability to skip or blacklist certain word strings, thanks to a newly updated version of Docuscope created by Suguru Ishizaki. At some point, we will open this can of worms–actually modifying Docuscope’s original tagging protocols–but not yet. There is still more to be learned from the results from an unmodified Docuscope: when we don’t touch the contents of its internal dictionaries, we have the ability to compare results across periods or corpora.
In this case, we learn that Docuscope is sensitive to human editorial intervention in texts. So sensitive, in fact, that it produced an almost complete clustering of Shakespeare’s plays in the larger group of 320 that we profiled in the online draft of our “Hundredth Psalm” article.
The large cluster of Shakespeare plays that resulted from our initial comparison of Globe texts with Mueller's semi-algorithmically modernized TCP plays
Once we realized that this grouping was at least partly artifactual–a product of different editorial procedures applied to our combined corpus–we eliminated the LATs that were registering this difference (TimeDate and LangReference). Of course, by eliminating these, we lost their sorting power on the rest of the corpus, so there was a tradeoff. But we felt that it was not fair to give Docuscope this kind of advantage in sorting text when it was the result of modern editorial intervention. In the future, we might blacklist a word like [’tis] so that we can retain the rest of the category, but I don’t think this is necessary. What really needs to happen is that, in our editorial preparation of texts and corpora, we must ensure that no set of texts is isolated from the others through special editorial preparation. The fact that “anything goes” in the current TCP collection – it is full of various compositorial and printhouse styles and conventions – is probably a good thing. And in any event, we still see authors’ works and genres clustering together even where printers are multiple. Here, now, is one of the new Shakespeare clusters once the editorial “tell” of certain types of punctuation was removed:
New clustering of Shakespeare's plays with TimeDate and LangRef eliminated from analysis
Now we see that plays by Munday, Heywood, Marlowe, Shirley, Rowley, Webster, Middleton, and Massinger are showing greater similarities with Shakespeare: the variability of their punctuation is not being used against them. Within the Shakespeare plays that do cluster together, we see some of the same similarities–Coriolanus with Cymbeline, for example. But the terms on which Shakespeare’s plays are related to each other are now more limited–we have eliminated two categories of LATs that may have been sorting Shakespeare’s plays with respect to each other. This relative loss of sorting power within Shakespeare’s works seems tolerable to us, however, because it allows for a more meaningful portrait of Shakespeare’s relationship to other dramatists of the period. What excited us about this large diagram was that it says something about 150 years of early modern drama as a whole, inasmuch as that whole could be represented by over 300 works.
Here is the entire diagram, then, constructed without the LATs that capture the nineteenth-century modernization of the Shakespearean texts. (Many thanks to Kate Fedewa for helping us create this large image.)
Revised dendrogram comparing early modern plays from the TCP collection and the Globe Shakespeare (click on image in new screen to zoom)
Two items worth mentioning: today I had a chance to hear the new record from the Steve Lehman Quartet called Travail, Transformation and Flow, which shows off some of what is new in spectralism, an aesthetic that involves analyzing a tone from a single instrument with a computer and developing improvisations out of its overtone series. The album — check out “Echoes,” which can be downloaded free here — reminds me of recordings I once heard of glass harmonicas, which are really sets of rotating glasses filled with water that “sing” when touched, like a champagne glass rubbed on its rim. The music shimmers like a school of fish: you hear a set of tones developing in one of his arpeggiated, darting solos and it fans out in a number of semi-dissonant directions. It reminds me also of the sound of those prayer bowls that are struck during meditation. Forerunners of spectralism include Debussy, Bartok, Messiaen and Stockhousen, but the music seems to go beyond any of these influences, especially when it takes the form — in the case of Lehman’s quartet — of an octet with tuba, bass, a few horns and an incredible vibraphone player who is constantly charting the harmonic offramps. There is something vaguely medieval about this music in the way it interlaces and suspends dissonant moments in a progression. I would not want to listen to Lehman’s music in a cathedral, however.
The Maya Lin Systematic Landscapes show at the Corcoran was also interesting, particularly the large massing of cut 2x4s into a kind of wooden berm in the middle of on the galleries. The piece, 2 x 4 Landscape looks an awful lot like a digital scan of a small geographical feature, one that has been recreated in physical form with all of its discrete jumps and bumpy texture: the model has become the object. I liked seeing the Lin exhibit after hearing Lehman’s piece because it reminded me of the ways in which some pieces of music or art acquire the status of diagrams or maps of their own construction. Apparently a mathematical algorithm called a Fast Fourier Transform is done on the initial tones in a spectralist analysis, since this pulls out aspects of the overtone series that you or I wouldn’t “hear” immediately. The composition then calls attention to these facts, which you somehow recognize. I thought the Lin piece does something of this as well: it shows you the way in which a hill, landscape or model of the same is composed of many possible paths through the terrain — across, diagonal, up and down — and that each of these vectors or “traverses” will provide you with a different sequence of ups and downs. A landscape or composition, that is, becomes a vector through a table of values. We could think of a text in a similar manner as well. (I’ll be posting more in this in the future.)
Several months ago I had the idea of taking a concordance of a text and then create a shape using the weightings of these words as heights, radiating from the most common in the center to the least common at the perimeter. Such a shape or sculpture could look like Lin’s 2 x 4 — it is a physical model of one set of “magnitudes” that defines the text — but would also be something other than a text. Take ten texts by two writers. Place the most frequent word of the first work in the center at height n1 (representing the number of times that word occurs in the work), then begin a clockwise coil starting at one position “north,” here at height n2 representing the number of occurrences of that word. Move next one position east (diagonal from the original origin) and place n3, then south for n4, south again for n5, then west for n6, etc. Now, if you created shapes for all ten works and then gave the surfaces to a topologist, what are the odds that she or he could do an author attribution? The point here is that Lin is using landscape, at least in part, as a very large dataset, which is something you can do with texts as well. (They contain ravines, valleys, hidden depths…) Or a single note with its overtone series: this too can be a starting point for meditation, analysis and improvisation, since there is “more to it” than just the note. Lin and Lehman are both artists who are interested in elemental phenomena that are really bundled sets of relationships. The bundles can be teased apart, made explicit, and expressed in a more vivid form: a systematic landscape or an improvisational spectrum.
I wanted to say a little about a problem we encountered early on when we began counting things in the plays, a problem that gets us into the question of what might be a trivial versus a non-trivial indicator of genre on the microlinguistic level. Several years ago Hope and I began a series of experiments with the plays contained in Shakespeare’s First Folio, feeding them into Docuscope — a text-tagger created at Carnegie Mellon — to see if we could find any ordered groupings in them. The results of that early work were published in the Journal for Early Modern Literary Studies in an article called “The Very Large Textual Object: A Prosthetic Reading of Shakespeare.” I will say more about Docuscope in subsequent posts, but suffice it to say here that it differs from other text-taggers in that it embodies a phenomenological approach to texts. (For the creator’s explanation of how it works, see an early online precis here.) Docuscope, that is, codes words and “strings” of words based on the ways in which they render a world experientially for a reader or listener. The theory behind how texts do this, and thus the rational for Docuscope’s coding strategy, is derived from Michael Halliday’s systemic-function grammar. But what is particularly interesting about Docuscope is the human element involved in its creation. The main architect of the system, a rhetorician named David Kaufer, spent 8 years hand-tagging several million pieces of English according to their rhetorical function, and then expanded out this initial tagging spread with wild-card operators so that Docuscope now classes over 200 million strings of English (1 to 10 words in length) into over 100 distinct categories of use or function.
Obviously there is a lot to say about the program itself, which represents a “built rhetoric” of sorts, one that has emerged through the interplay of one architect, his reading, and the texts he was interested in classifying. In any event, when Hope and I fed the plays into Docuscope, we had to make some initial decisions, and the first was whether to strip anything out of the plays we had obtained from the Moby online version. (We were already thinking about the shortcomings of this conflated, edited corpus as opposed to the text of the plays as it exists in various states in the First Folio, but we had to make do since we were not yet ready to modernize the spelling of F and decide among its internal variants.) So with the Moby text, we had things like Titles, Act and Scene Numbers, and Speech Prefixes (Othello, King Henry, Miranda, etc.). The speech prefixes created the greatest difficulty, because in the history plays the word “King” is, as you can imagine, used an awful lot — it appears in the speech prefixes of characters over and over. And because Docuscope tagged “King” as one of its visible tokens (assigning it to the “bucket” named “Common Authority”), this particular category was off the charts in terms of frequency when it came time to do unsupervised factor analysis on the frequency counts obtained from the plays. (I’ll post more on factor analysis in the future as well.)
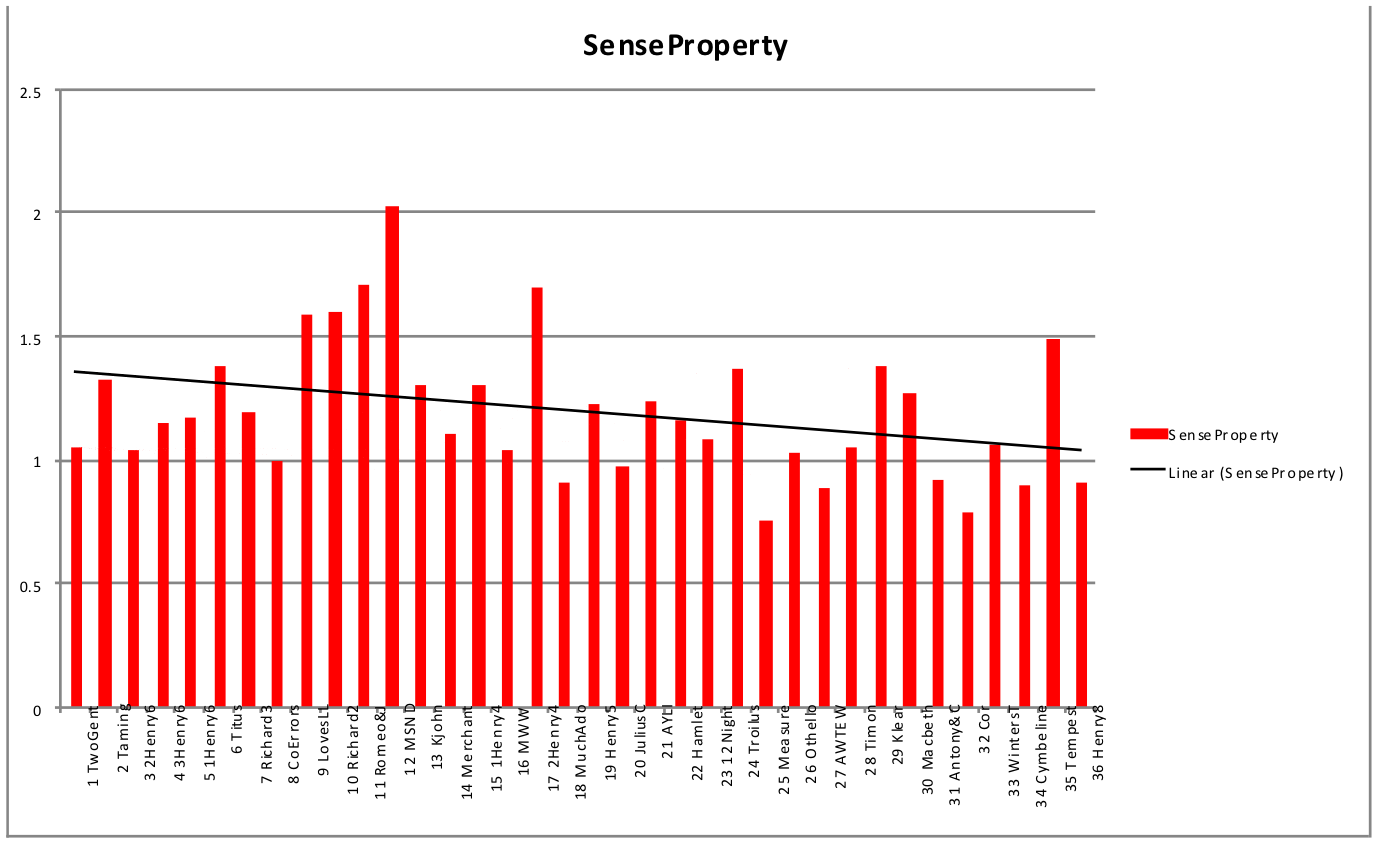
Here’s the issue. In the end, we decided that it was “cheating” to let Docuscope count “King” in the speech prefixes, since this was a dead giveaway for History plays, and we wanted something more structural — something more buried in the coordination of word choices and exclusions — to serve as the basis of our linguistic “recipes” for Shakespeare’s genres. As the article shows, we were able to find such a recipe without relying on “King” in the speech prefixes. Indeed, subsequent research has shown that plural first person pronouns combined with a the profusion of concrete, sense objects are really the giveaway for Shakespeare’s histories. (They are also “missing” certain things that other genres have: this combination makes histories the most “visible” genre, statistically speaking” that he wrote.) But is it really fair to decide that certain types of tokens — King in the speech prefix, for example — are superficial marks of history as a genre, and so not worth using in an analysis? Isn’t there a certain interpretive bias here, one that I have and in a sense want to argue for, against the apparatus of the play in favor of something like a deeper set of patterns or stances? To argue for such an exclusion, I would begin by pointing out that they are an artifact of print and are not “said” (even if they are used) in performance, but there is still something to think about here.
A Google search algorithm looks for the “shortest vector” or easiest “tell” that identifies a text as this kind or that — even if it is one of a kind. But those of us who are interested in genre must by definition not be interested in the shortest vector or the easiest tell. We are looking for the longer path. The book historian in me, however, says that apparatus is important, and that “accidental” features never really are. So this is something I want to think more about.









{kind=link}