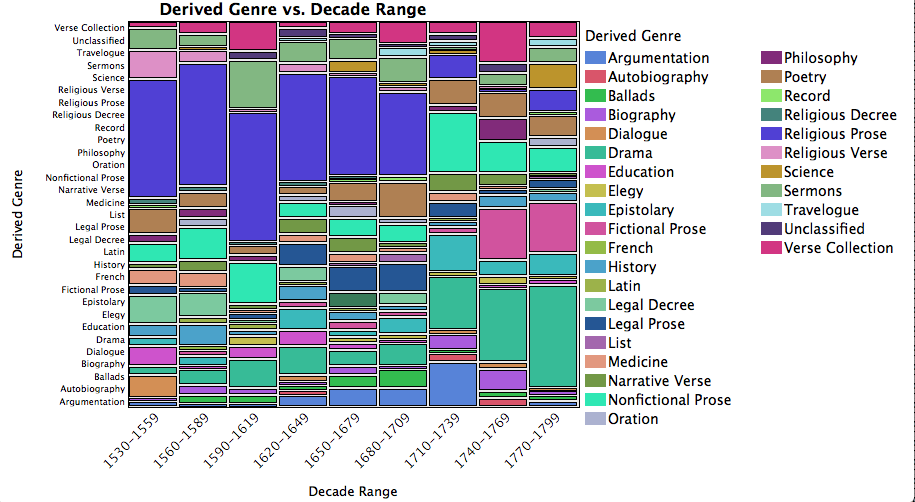
Some features of the corpus, visualized here over time. Many of the linguistic and topical trends that we find in this data set will express the state of the corpus at a given moment in time. I have divided up the time series into groups containing three decades apiece. The visualization above displays the relative number of titles that we have classed according to the genre — what we are calling “Derived Genre” on the Y axis. Note that the size of plots in the stacked bar graphs does not represent the size of the texts involved: vertical size represents the number of items in that time period that have been so labeled. The names at left represent the order in which the different genres have been stacked, from bottom to top. At right, an alphabetical list of the genres designated by their colors.
An obvious trend that will be born out in the analyses that follow: the corpus contains a lot of what we are calling Religious Prose items from 1530-1709, but after this point, the number of Religious Prose items declines. After 1709, we see more drama (after a compression during the closure of the theater’s mid-century) in the aqua color, along with more Nonfictional Prose (cyan), Fictional Prose (rose), and perhaps too Verse Collections (magenta). These shifts in the relative proportions of different genres should not be taken as representative of everything printed during each of these periods. The corpus itself is a small sample of that larger field. But because the selection of texts was random, excluding only items of less than 500 words, we expect there to be some trends within the corpus that are representative of larger trends in print culture. As the project develops, we should have a better sense of just what you can learn from 1080 texts in a field that is much larger.
Since we measured word types (according to Docuscope Junior LATs or topics) as a proportion of all words in a given text, the length of individual texts should not significantly affect the distribution of those types of words. Nevertheless, it helps to see the lengths of different kinds of texts. Our text tagger treats the spaces between words as tokens so that word combinations can be accommodated or excluded; the sum of tokens on the y-axis thus includes these with the words and punctuation:
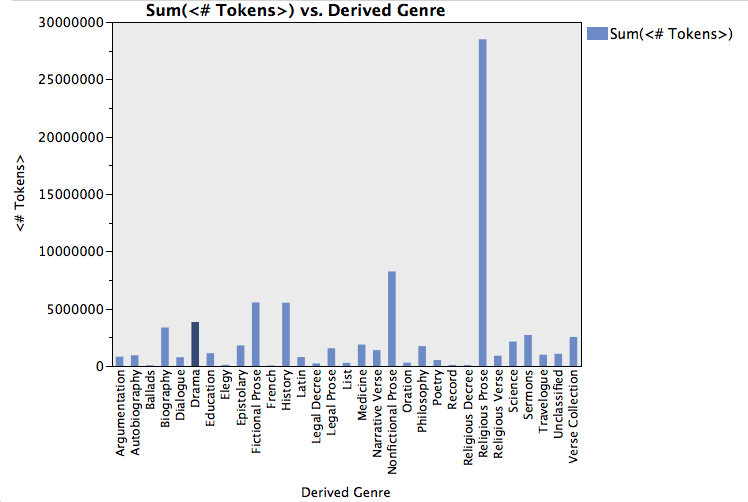
Unsurprisingly, Religious Prose texts tend to be quite long, whereas Ballads are almost always short. Fictional Prose texts are reasonably long, as are Biographical texts. All of this is in keeping with what I, at least, would expect from texts belonging to these genres. It should be noted that the genre designations you see in our spreadsheet are subjective and so arguable. We asked a member of our team, Jason Whitt, to apply them. Someone else looking at this corpus might come up with different designations, and we understand that there will be debate on this score. You can see the full list of our classifications by consulting the “Genre” column in the spreadsheet of the corpus.
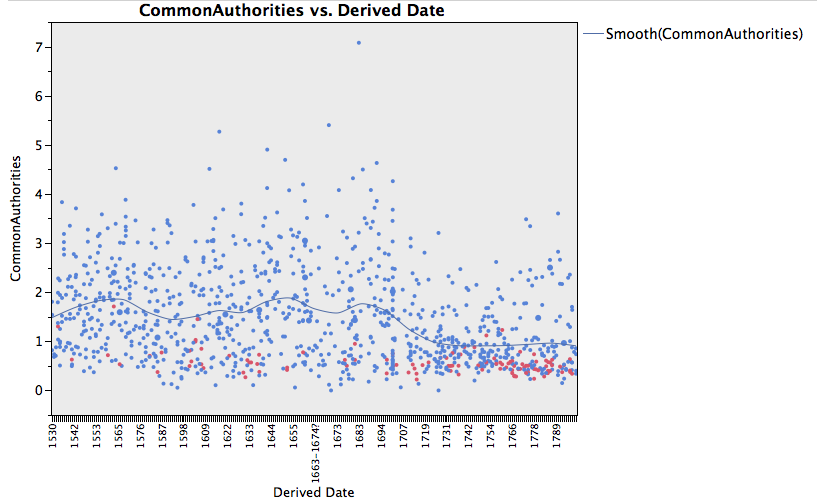
Noting the relative decline in the amount of items designated as Religious Prose in the corpus over time, I became curious about a seemingly parallel decline in words that bear the DSJ tag “Common Authorities” — words mentioning entities invested with some type of communally sanctioned power (God, king, church, etc.). You can see the declining proportion of such words in texts as the decades roll on. In the chart below, the position of dots on the y-axis shows the percentage of tokens in each text (each dot) that were given the “Common Authorities” tag. Please note that dramatic texts in this graph have been colored red.
As always, we like to see the tokens in action, and so I offer a sample text that is high in this variable. The text is, The Epiphanie of the Church (1590), and can be consulted below.
Comments
One response to “Visualizing English Print, 1530-1800, Genre Contents of the Corpus”
The three peaks for CommonAuthority correspond roughly to the reformation (and its aftermath in the debate over succession) and the two revolutions. Interestingly, they seem to lag by a few years from the date I’d have expected. i.e. The first peak falls almost at 1560 and the second at the Restoration – both of these are plausible but, for example, I’d have expected the explosion of print and political/religious tracts that accompanies the outbreak of the civil war to be a high point. Might this at least partially be an artifact of how the texts are dated and binned into decades?
Also, it seems the pattern would be much clearer if this were plotted with a log scale for the y axis.